
취미가 좋다
ResNet / ResNext 정리 본문
ResNet

VGG 네트워크를 통해 네트워크 모델이 깊어질수록 성능이 좋아진다는 것을 확인했다.
하지만 깊이를 늘리는 데 한계가 있었고, VGG에서는 16-layer 이후 성능 향상이 거의 없었다.
ResNet은 VGG보다 더 깊은 네트워크를 만들어도 성능의 향상을 가져오도록 하였다.
아래를 보면 기존에 사용하던 plain network와 ResNet을 적용한 네트워크를 비교할 수 있다.
입력 x를 출력에 더해서 H(x)=F(x)+x 의 F(x)를 학습시킨다.

plain으로 학습했을 때는 34-layer가 18-layer보다 깊은데도 에러율이 더 높았다.
ResNet을 적용한 후에는 더 깊은 네트워크가 에러율이 더 낮은 것을 확인할 수 있다.

bottlenect resnet
연산 시간을 줄이는 방법이다.
1x1 conv로 차원을 줄인 후, 3x3 conv 연산을 수행하고, 다시 1x1 conv로 차원을 복구한다.
3x3 conv를 2번 연속으로 하는 기존 구조보다 연산량이 줄어든다.
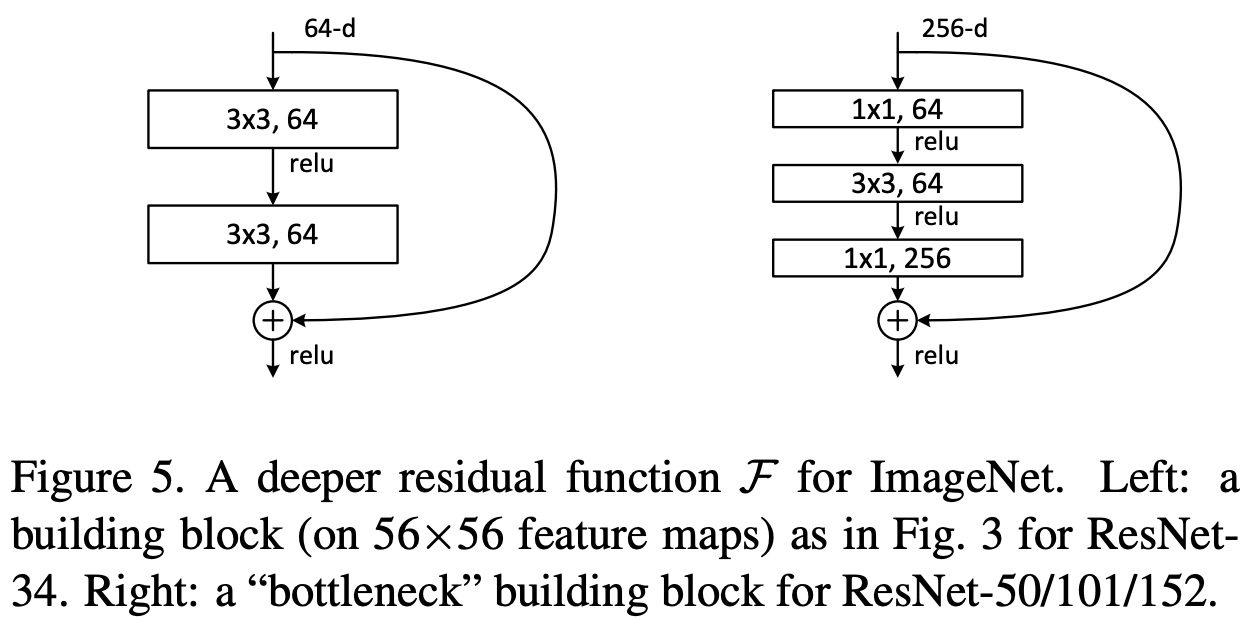
identity block : shortcut connection으로 만든 기본적인 block
convolution block : 입력 x를 출력에 더해주기 전 1x1 conv를 한 block

두 block을 여러개 쌓아서 stage를 만든다.
여러 stage를 쌓아서 아래와 같은 깊은 네트워크를 만든다.
resnet 101
5개의 stage가 있다.
2,3,4,5 stage에서 block이 사용된다.
conv block은 stage에 하나씩만 사용, i block은 여러 개 사용한다.

ResNext : Aggregated Residual Transformation for Deep Neural Networks
같은 block을 반복적으로 구축하면, 더 적은 파라미터로 이미지 분류가 가능하다.
더 깊고 큰 차원보다, C (cardinality)를 높이는 것이 분류의 정확도를 높인다.
cardinality : 똑같은 형태의 building block 의 개수
아래와 같은 Inception model 의 주된 아이디어인 split - transform - merge 구조를 가진다.
1개의 입력이 여러 방향으로 쪼개진다는 것은 Inception resnet과 같다.
각 path 별로 같은 layer 구성을 가진다는 점은 다르다.
이렇게 같은 layer 구성을 가지는 것을 grouped convolution 이라고 한다.

ResNext 는 다른 모델들 (ResNet-101/152, ResNet200, Inception-v3, Inception-ResNet-v2) 보다 더 간단한 구조를 가졌지만 더 나은 성능을 가진다.
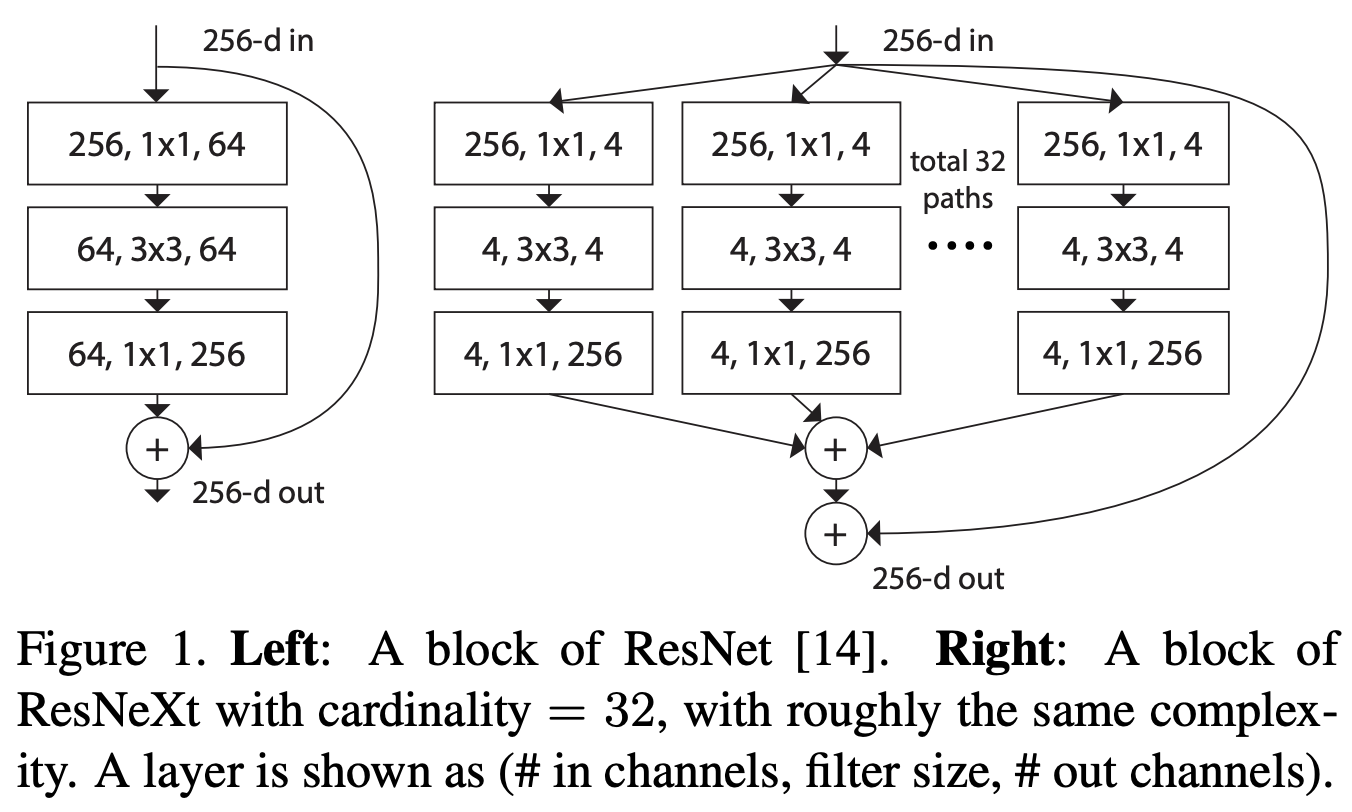
아래와 같이 ResNext-50을 구성하고, ResNet-50 과 매우 비슷하다.

ResNet 에서는 하나의 블록에 2개의 convolution layer 의 깊이는 2 였다.
ResNext 에서 depth 가 2라면 아래의 사진처럼 block이 구성된다.
깊이가 2이기 때문에 group convolution 의 의미가 없어져서 성능 향상이 없기 때문에, depth가 최소 3 이상이어야 한다.

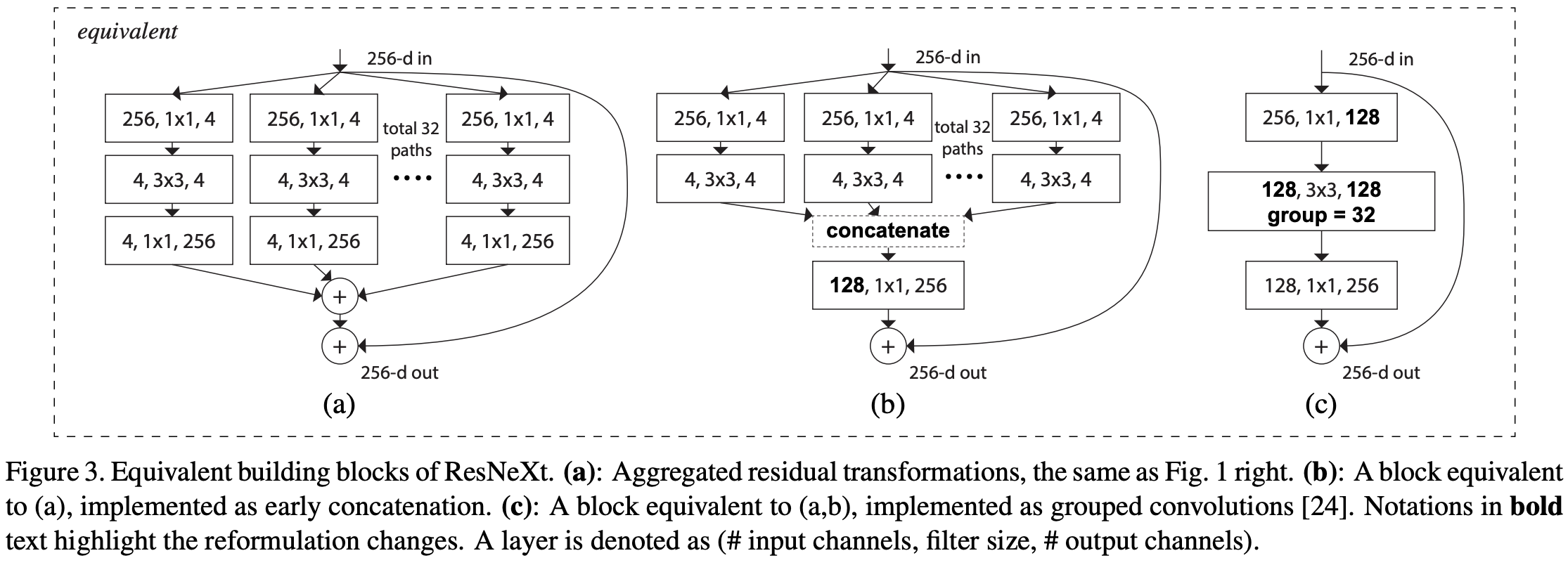
아래 3개의 block은 모두 equivalent 하다.
(a) 채널 수가 4개인 32개의 path 가 병렬로 실행된 후 합해진다.
(b) 채널 수가 4개인 32개의 path 가 병렬로 실행되고, 1x1 conv 로 채널 수를 다시 늘리지 않고 concatenation 한 후 1x1 conv를 수행한다.
(c) group convolution을 한다.
cardinality 가 증가할수록 error가 줄어드는 것을 보여준다.
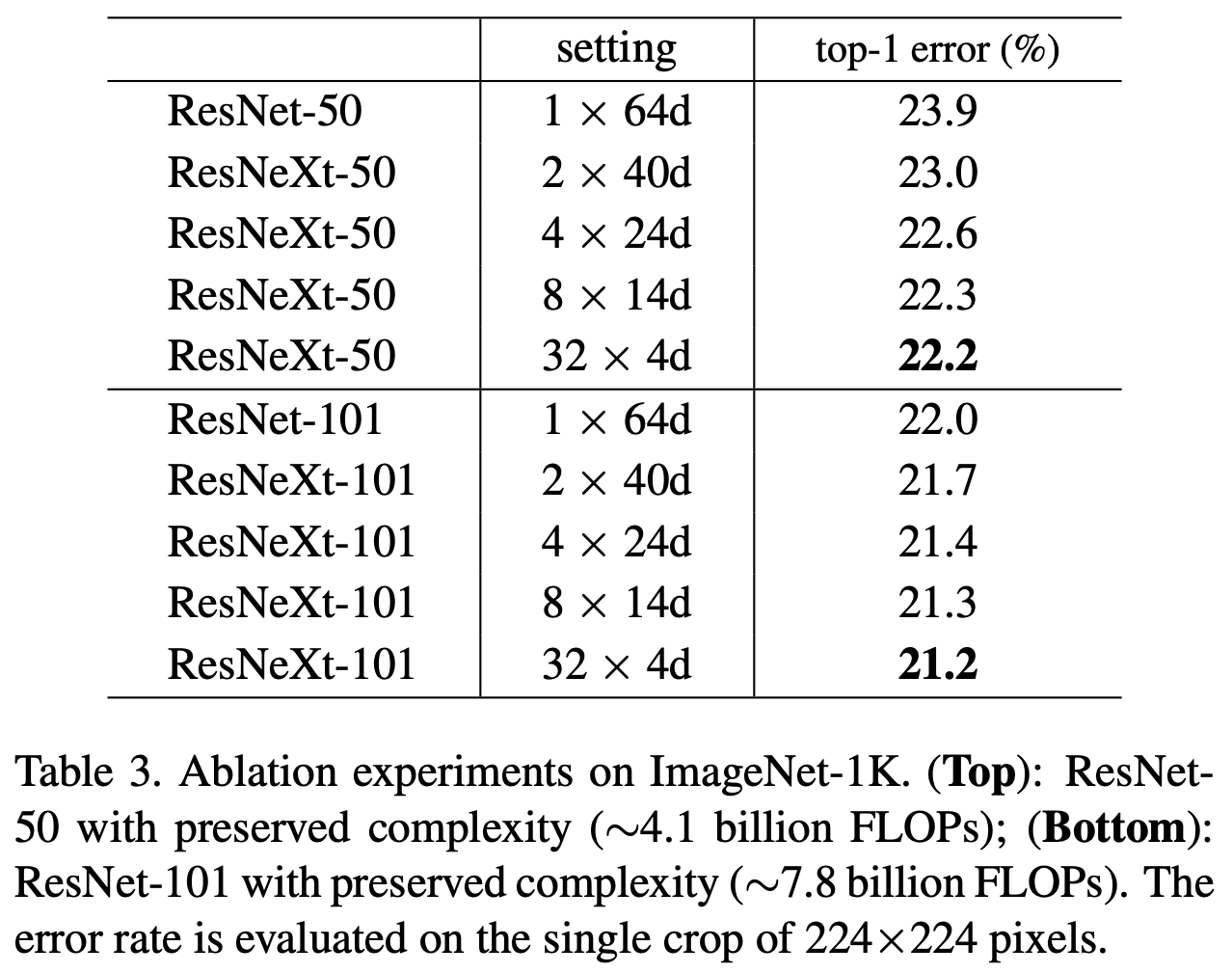
기본적으로 네트워크가 깊고, layer가 넓을수록 성능이 좋다고 알려져있다. (deeper, wider)
하지만 아래 표를 보면, ResNet을 깊고 넓게 만드는 것보다 cardinality 를 높이는 것이 error 를 더 낮추고 있다.

'논문' 카테고리의 다른 글
| Fast and Accurate Model Scaling 논문 정리 (0) | 2021.04.16 |
|---|---|
| ResNeSt : Split-Attention Networks 논문 정리 (0) | 2021.03.19 |
| SENet : Squeeze-and-Excitation Networks 정리 (0) | 2021.03.18 |
| Mask R-CNN 정리 (0) | 2021.03.17 |
| PixelLink : Detecting Scene Text via Instance Segmentation 논문 리뷰 (0) | 2021.02.13 |



