
취미가 좋다
ResNeSt : Split-Attention Networks 논문 정리 본문
ResNeSt : Split-Attention Networks
Facebook, UC Davis, Snap, Amazon, ByteDance, SenseTime
ResNet 계열 image classification 모델이다.
1. Introduction
ResNet 이후에 좋은 성능을 가지는 모델들이 나왔지만, ResNet 이 simple & modular 한 구조를 가지기 때문에 아직까지도 많이 사용된다.
ResNet의 단점은 크로스 채널 정보를 반영하지 못하고 있다는 것이다.
이 논문의 ResNeSt 는 ResNet 의 residual block 을 replace 하는 새로운 block을 제시한다.
유사한 모델 complexity를 가질 때, 기존의 ResNet 계열(ResNext, SENet, SKNet)과 비교했을 때, 가장 높은 accuracy를 가진다.
또한 Object Detection / Segmentation 처럼 다양한 downstream task에 대해서 backbone 으로 사용하면 성능이 올라간다.
2. Related Work
Grouped Convolution
feature map에서 채널 축으로 여러 그룹을 나누고, 마찬가지로 filter 도 여러 그룹으로 나눈다.
앞쪽 채널의 그룹은 filter의 앞쪽 과 연산, 뒤쪽은 뒤쪽과 연산한다.
그 결과를 concat 해서 최종 결과를 얻는다.

하지만, 앞쪽 그룹은 앞쪽 그룹에서만 연산을 하기 때문에, 채널의 뒤쪽의 정보를 반영하지 못한다고 생각할 수 있다.
즉, 채널 그룹간 단절로, 성능을 저하시킨다고 생각되어 Channel Shuffling 을 진행한다.
shuffleNet 에서는, 중간에 채널을 셔플하여 채널 간 단절을 막아, 문제를 해결하려 했다.

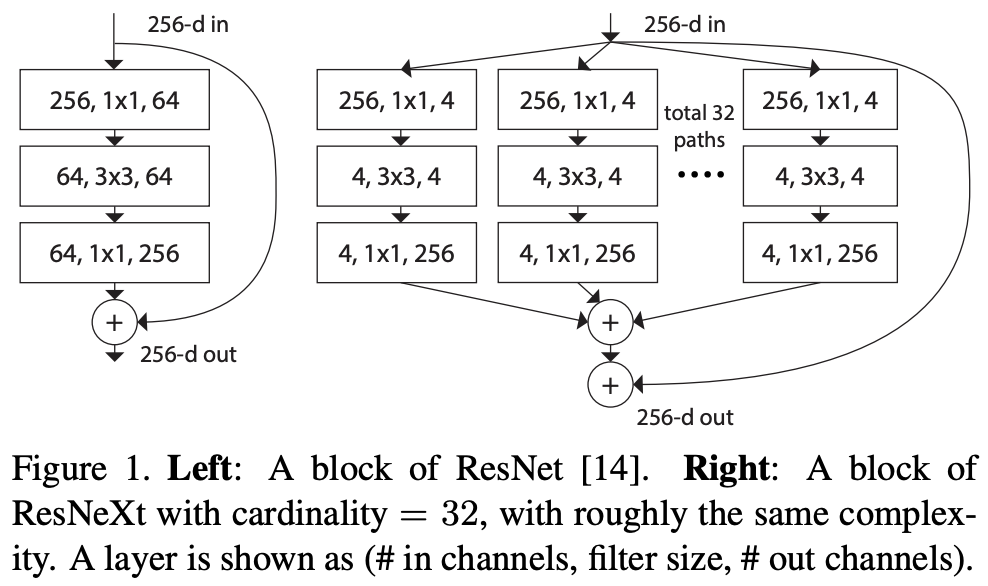
ResNext
cardinality 를 처음 사용하였고, inception 처럼 멀티 path (branch)를 가지고 있다.
이때, branch의 개수가 cardinality 라고 한다.
layer의 depth, width를 늘리는 것보다 cardinality 가 많아지면 accuracy 가 향상된다.
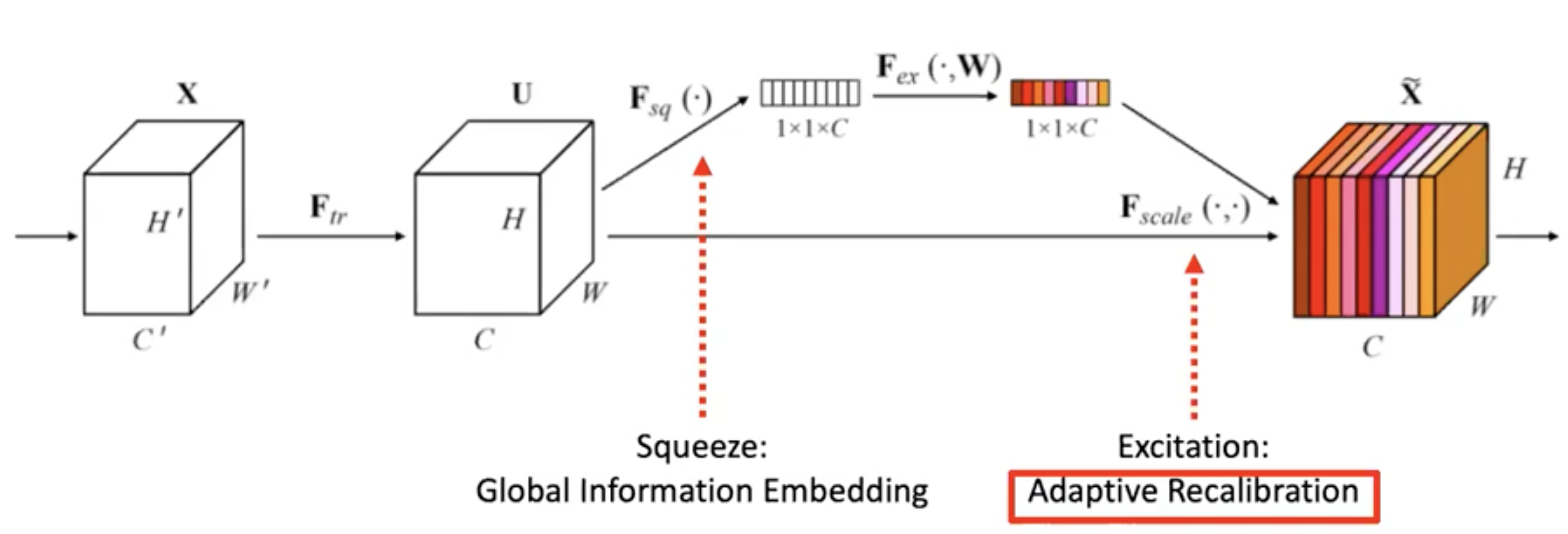
SE-Net
channel-attention mechanism 을 도입하였다.
feature map 의 각 채널들은 동일하게 중요하지 않다.
fully-connected layer 몇 개로 attention weight를 계산하는 네트워크를 삽입하여, 각 채널에 대한 가중치 weight를 만든다.
그 weight를 기존 feature map에 곱하여, 중요한 채널을 더 중요하게 만든다.
이 마지막 과정을 recalibration 이라고 한다.
SK-Net
feature-map attention 을 도입하였다.
들어오는 입력 feature를 두 개의 다른 branch로 보낸다.
한 쪽은 3x3 kernel, 다른 쪽은 5x5 kernel 을 사용한다.
두 branch가 서로 다른 receptive field size를 가지도록 하여, 나중에 결과들을 aggregation 한다.
여기에서, 어느 쪽 path에 온 feature들이 더 중요한지 결정하는 attention weight를 계산하는 네트워크를 중간에 삽입한다.
weight를 기존 feature map에 곱하여, 입력에 따라서 어떤 path의 feature map의 정보를 중요하게 여길 건지 dynamic 하게 결정한다.

3. Split-Attention Networks
cardinality 와 split을 혼합해서 사용한다.
feature map의 채널을 K개의 cardinal group으로 나눈다.
하나의 cardinal 그룹 안에서 R개의 split(subgroup)(Radix) 로 나눈다.
따라서 전체 split 개수는 K*R 개 이다.

Split-Attention block은 ResNet의 Residual block 전체를 대체한다.
feature map이 K 개의 cardinal로 나뉘어 입력으로 들어가 연산을 수행한다.
그 결과를 concatenation → 1x1 conv → skip connection으로 입력과 더해주면 최종 결과가 생성된다.
만약 cardinal 안을 black box라고 생각하면 전체 구조는 ResNext와 동일하다.
cardinal 안은 R개의 branch(split)가 존재하고, 각 branch는 먼저 1x1 conv, 3x3 conv를 수행한다.
(cardinal 안의 branch가 하나일 때,) 여기까지는 ResNext와 동일하다.
ResNext와의 차이점은 cardinal 안에 이런 작업을 수행하는 branch가 하나가 아니라 여러 개라는 것과, 그것을 합치는 과정(split attetion)이 있다는 것이다.
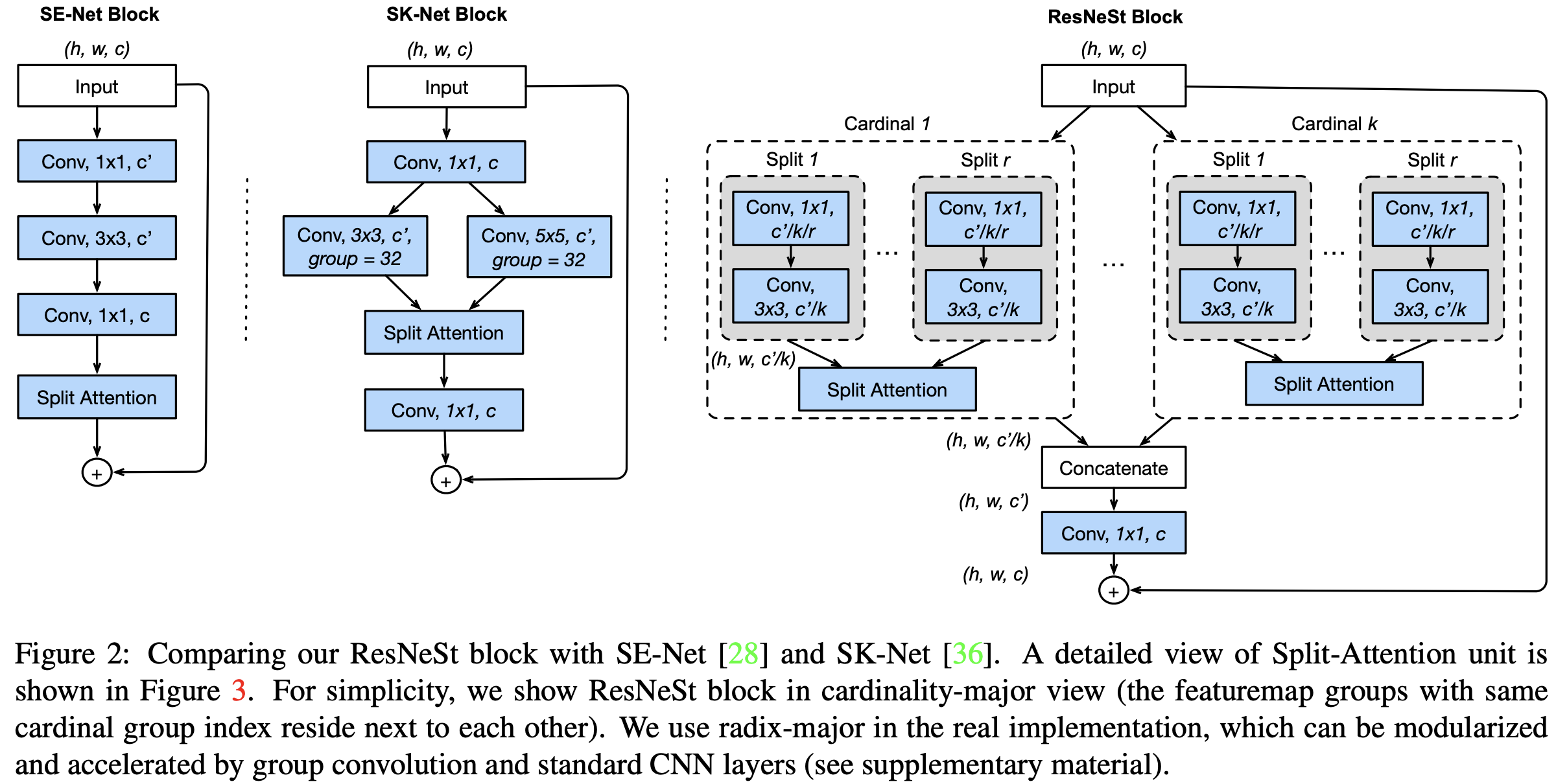
split attention
split 개수 R개만큼 입력이 들어오면, attention weight를 계산하고 각각의 입력에 곱한 후 합한다.
attention weight를 계산하는 부분은, GAP -> dense layer 2개 -> r-softmax 으로 구한다.
각 split 에 대해서 attention weight를 적용하기 때문에 논문의 이름을 split-attention으로 이름을 정하였다.
만약 split R=1이라면 attention weight를 sigmoid로 계산하기 때문에, 해당 cardinal 별 weight를 가지게 된다.
즉, cardinal은 입력 feature map의 채널을 나눴으므로, 채널별 attention을 나누는 SENet과 유사한 동작을 한다.
만약 split R=2라면 split attetion은 각 cardinal에 대해 SK-Net과 유사한 attention 역할을 수행한다.


equivalent Radix-major implementation
split과 cardinal의 순서를 바꿔서, split 안에 cardinal이 있는 형태로 구현해도, 최종 결과는 동일하다.
기존에는 작은 group 별로 attention을 적용해서 concat을 했다면, 이 경우에는 작은 group을 먼저 concat 한 후 그에 대한 attention을 적용하였다.
radix-major로 하면 구현이 쉽고, 기본적인 CNN operator를 그대로 사용할 수 있어서 더 modular 해진다.
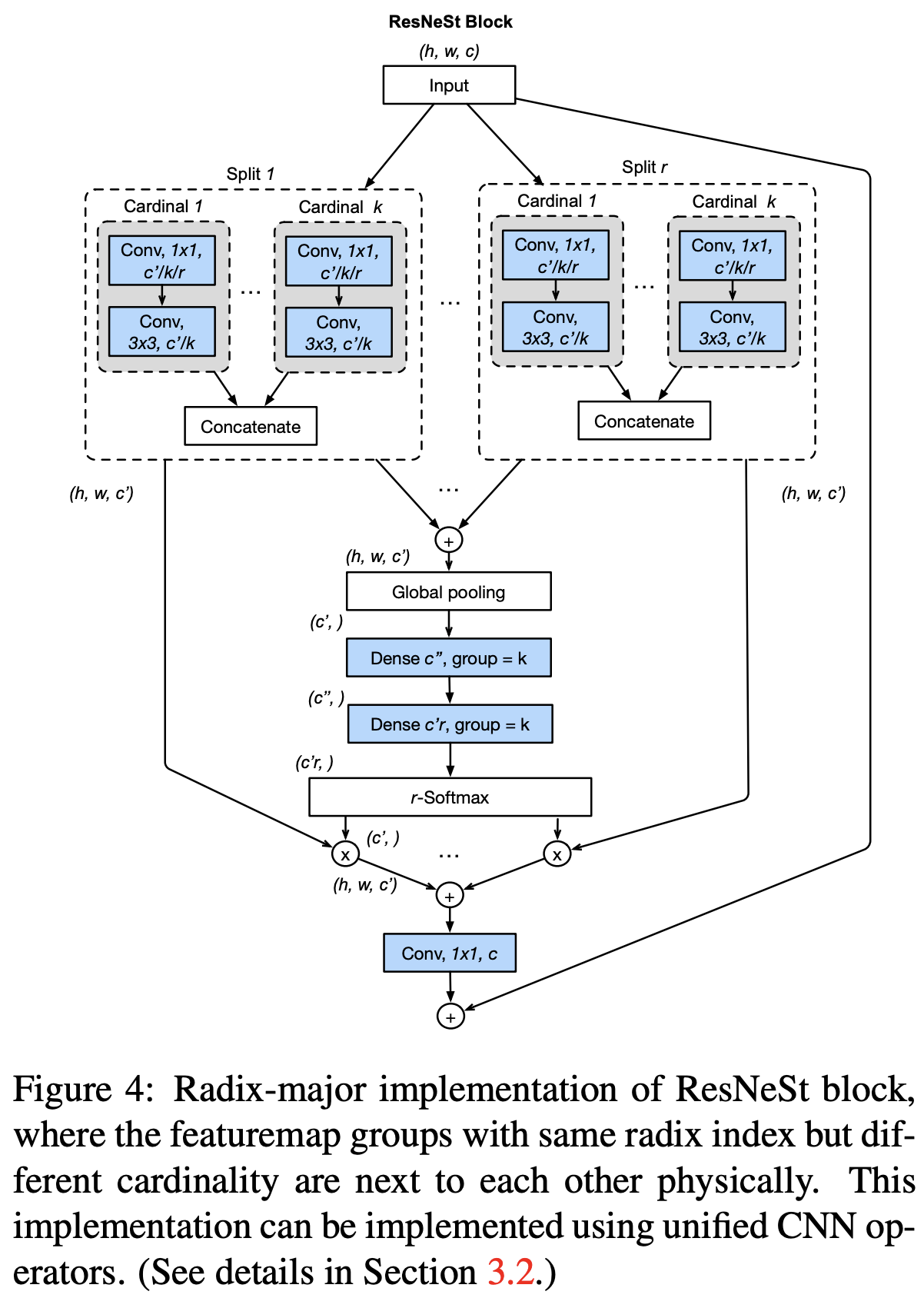
4. Network and Training
추가적으로 성능을 올린 방법이 여러 가지 있다.
Bag of Trics for image classification with convolutional neural networks 논문의 기법들을 좀 더 추가하여 적용하였다.
Tweaks from ResNet-D
ResNet 구조의 총 3가지를 변경한다.
1) ResNet input 부분에 있는 7x7 conv를 3x3 conv 3개로 치환한다.
반복되는 Residual block(stage) 내부를 보면 2개의 path가 있다.
2) 기존에는 왼쪽 path의 1x1 conv 에서 stride=2 로 두었기 때문에, feature map의 정보를 많이 잃어버린다.
stride를 1x1 conv 뒤에 따라오는 3x3 conv로 옮겨서 feature map 정보를 조금 더 가지고 있도록 하였다.
즉, feature map size를 줄이는 것을 뒤로 미뤘다.
3) 오른쪽 1x1 conv의 stride=2 를 대신에, AvgPool으로 feature map 사이즈를 줄인 후 conv 수행한다.

여기까지가 Bag of Trics 논문의 내용을 적용한 것이고, 추가적으로 몇 가지를 더 수행하였다.
3x3 conv stride=2 를 하지 않고, 3x3 conv stride=1 후에 AvgPool 을 하여, feature map을 더 뒤에서 줄인다.
아무래도 늘어난 계산량을 줄이기 위해서, AvgPool 과 3x2 conv 순서를 바꾼 것을 ResNeSt-fast 라고 한다.

training strategies 은 아래와 같다.
label smoothing
gt에 1, 0이 있으면 1보다 살짝 작고, 0보다 살짝 큰 값을 사용하여 regularization 효과를 얻는다.
mixup training
2개의 샘플을 뽑고, 두 개의 이미지가 다른 가중치를 가지고 alpha blending으로 섞이면 학습한다.
overfitting을 막는 효과가 있다.
autoAugment
google에서 쓴 논문으로, data augmentation에 강화 학습을 적용한 논문이다.
augmentation에서 쓰이는 대표적인 변환 16개(rotate, flip...)로 2개씩 pair를 만든다.
그 pair들을 넣었을 때, accuracy가 높은 것에 reward를 줘서 가장 성능이 좋은 24개의 pair를 찾았다.
ResNest 는 autoAugment 결과로 나온 24개의 pair를 그대로 사용하였다.

dropBlock
dropout을 CNN에서 사용할 수 있도록 확장하여 regularization 효과를 얻는다.
보통 conv layer에서 dropout을 안 쓰고, fully conv layer에서 사용한다.
그 이유는 conv에서 dropout 했을 때, 픽셀 간 연결이 끊어져도 다른 픽셀과는 여전히 계산을 하기 때문에, 별로 효과가 없다.
dropblock은 픽셀 단위로 끊는 게 아니라 사각형 형태의 특정 영역을 통째로 0으로 만든다.

5. Image Classification Results
기법을 조금씩 추가할 때마다 accuracy가 올라간다.
Variant의 s앞이 split, x앞이 cardi이고 d앞은 width(=channels) 이다.
split과 cardi를 작은 값으로 조합한 것을 볼 수 있다.
나중에 extreme한 값들로 실험을 했다고 하고, 추후에 Revision 할 때 추가된다고 한다.
그래서 논문엔 없지만 cardi도 늘리면 accuracy가 더 올라간다고 한다.
물론 속도는 더 느려진다.

다른 resnet 기반의 모델들과 비교했을 때, 좋은 성능을 보인다.
ResNet-101, ResNeXt 와 같은 다른 모델의 101보다 resnest 50이 더 성능이 좋다.
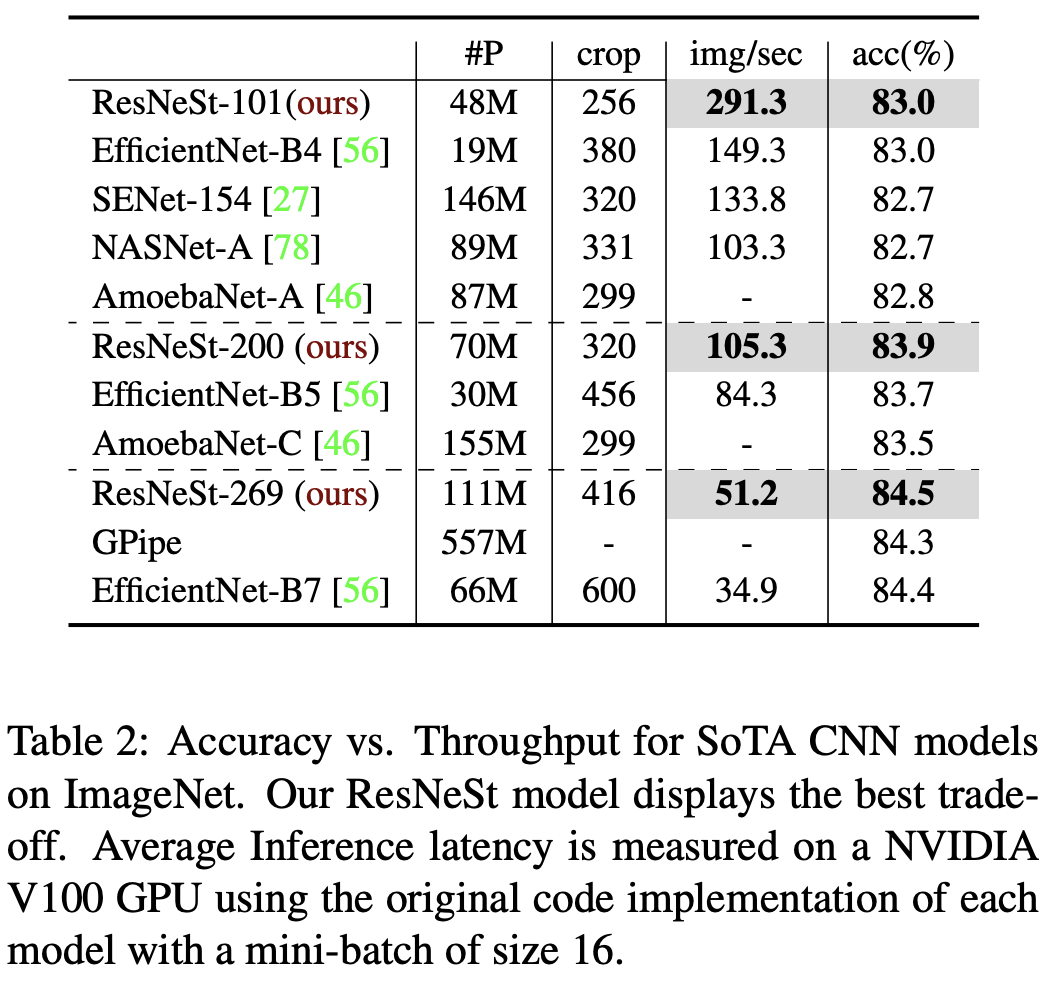
trade-off 결과이다.
동일한 latency 일 때 acc가 더 높고, 동일한 acc일 때, latency가 더 줄어든다.

6. Transfer Learning Results
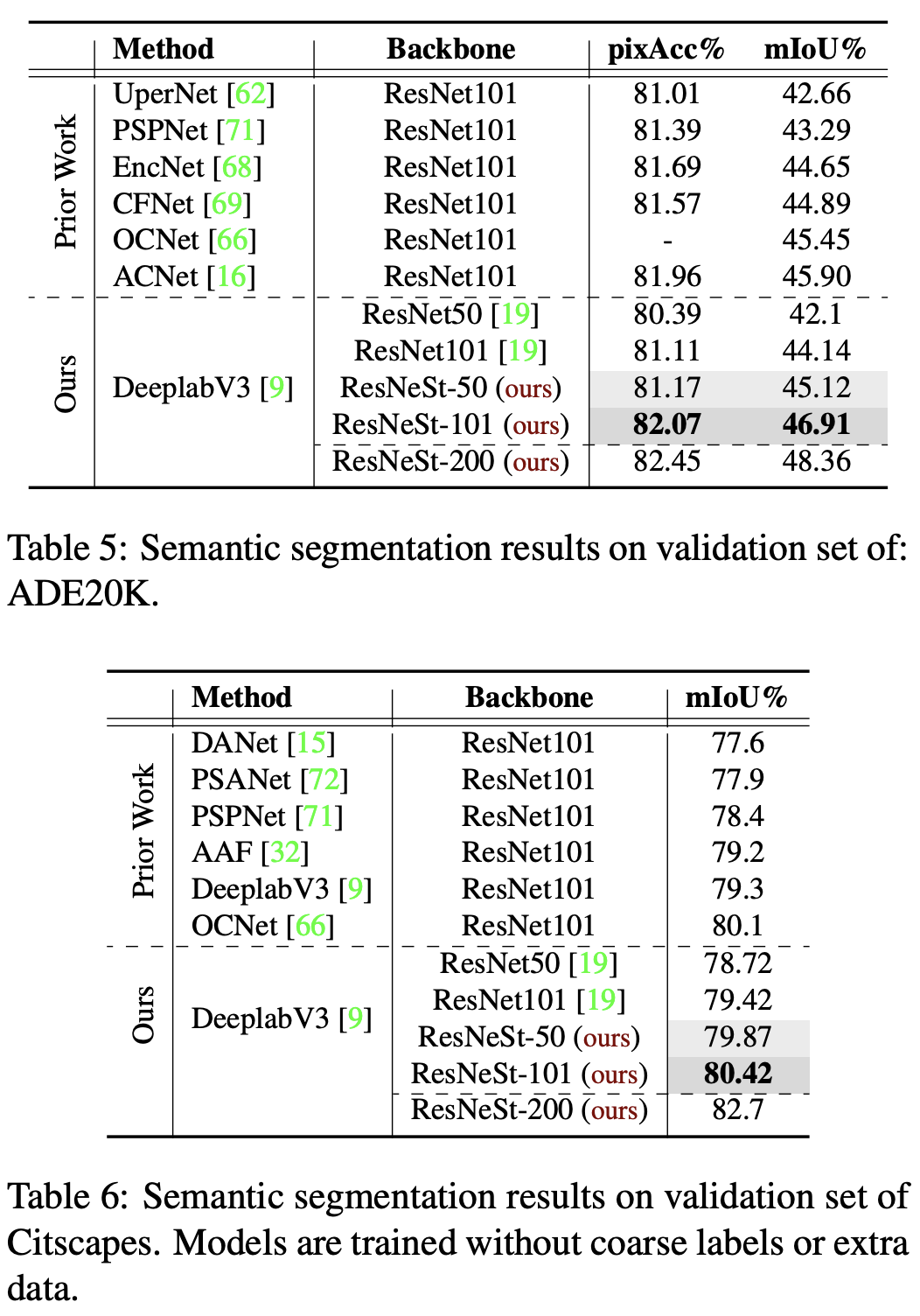
object detection / instance segmentation / semantic segmentation
cascade-RCNN는 mask-rcnn에서 마지막 classification layer를 cascade를 여러 번 한 architecture 이다.
백본을 resnet에서 resnest로 바꿨을 때 AP 상승하였다.
결론 : downstream task에서도 resnest을 유용하게 사용할 수 있다.


7. Conclusion
코드는 저자의 github에 공개되어 있다.
그 코드가 파이썬 패키지로 만들어져 있어서, 그냥 Import 해서 간단하게 사용할 수도 있다.
ResNeSt를 한마디로 요약하면, channel wise attention을 feature map group의 representation에 적용한 연구
resnet의 장점을 그대로 가지고 residual block을 대체하는 것으로, 모든 downstream task에서 성능을 향상시킬 수 있다.
아직 더 많은 실험으로, 제안한 네트워크의 potential을 검증할 필요는 있어 보인다.
ImageNet classfication에서 SOTA를 기록하려면, 새로운 네트워크를 제안하는 것으로는 한계가 있다. 자잘한 트릭과 튜닝 등을 적용해야한다적용해야 한다.
Jiyang Kang 님의 youtube를 보고 작성하였습니다.
'논문' 카테고리의 다른 글
| The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization 논문 (0) | 2021.05.13 |
|---|---|
| Fast and Accurate Model Scaling 논문 정리 (0) | 2021.04.16 |
| SENet : Squeeze-and-Excitation Networks 정리 (0) | 2021.03.18 |
| ResNet / ResNext 정리 (0) | 2021.03.18 |
| Mask R-CNN 정리 (0) | 2021.03.17 |



