
취미가 좋다
PixelLink : Detecting Scene Text via Instance Segmentation 논문 리뷰 본문
PixelLink : Detecting Scene Text via Instance Segmentation
Dan Deng, Haifeng Liu, Xuelong Li, Deng Cai
Abstract
대부분의 최신 STD(Scene Text Detection)은 bounding box regression의 딥러닝 기반의 방법을 사용한다.
그리고 text인지 non-text인지 구별하는 classification과 location regression을 예측한다.
regression은 bounding box를 예측하는데 핵심적이 역할을 하지만, text/non-text 예측이 semantic segmentation의 역할을 한다고 볼 수 있으므로 필수적인 것은 아니다.
그러나 이미지 속 text가 아주 가까워서 semantic segmentation으로 분리하기가 어려울 때가 있다.
그래서 이 문제를 해결하기 위해 instance segmentation이 필요하고, PixelLink는 이를 기반으로 하는 STD 알고리즘이다.
text instance는 먼저 같은 instance 내의 픽셀을 연결하여 나뉘어진다.
그 다음 location regression 없이 segmentation 결과로부터 text bounding box를 추출한다.
regression 기반의 방법과 비교하면 PixelLink는 비슷하거나 더 나은 성능을 가지고, 더 적은 데이터를 필요로 한다.
1. Introduction
text 읽기는 오랜 기간 관심의 대상이었고, text detection, text recognintion 두 가지 단계로 이루어진다.
localization으로도 불리는 detection은 이미지를 입력으로 받으면 이미지 속 text의 위치를 출력한다.
딥러닝과 object detection이 발전하면서 더 정확하고 효율적인 STD 알고리즘들이 제안되어왔다.
예를 들면, CTPN, TextBoxes, SegLink, EAST가 있다.
대부분의 이런 최신 방법들은 FCN을 기반으로 하고, 적어도 2가지를 예측한다.
1) text/non-text classification
이런 예측은 text bounding box의 픽셀일 확률로 사용될 수 있지만, 주로 regression 결과의 confidence로서 사용된다.
2) Location regression
text instance의 위치 또는 그들의 segmentation/slices 는 주로 reference boxes 또는 bounding boxes의 절대적 위치의 offset으로 예측된다.
SegLink에서는 segment 간의 연결도 예측된다.
이러한 예측들 이후, 후처리를 통해 최종 출력할 bounding box를 얻는다.
Location regression은 text detection 뿐만 아니라 object detection에서도 오래 사용되었으며, 효과적이라고 증명되어왔다.
그러나 위에서 말했듯이, text/non-text 예측은 regression 결과의 confidence뿐만 아니라, 위치 정보를 포함하고 bounding box를 직접 구할 수 있는 segmentation score map으로도 사용될 수 있다.
그래서 regression은 필수적이지 않다.
그러나 아래 사진을 보면 text instance는 때때로 아주 가까이 있다.
이러한 경우에 semantic segmentation으로 분리하는 것은 매우 어렵고, 때문에 instance 단위로 segmentation이 더욱 필요하다.

이 문제를 해결하기 위해 PixelLink를 제안한다.
bounding box regression 대신에, instance segmentation 결과로부터 text의 위치를 추출한다.
PixelLink에서 DNN(Deep Neural network)은 픽셀 단위의 두 가지로 학습된다.
하나는 text/non-text prediction이고, 나머지는 link prediction이다.
text instance 속 픽셀은 positive로 라벨링되고(text pixel), 그렇지 않으면 negative로 라벨링된다.(non-text pixel)
여기서 link 개념은 SegLink에서 영감을 얻었지만, 큰 차이가 있다.
모든 픽셀은 8개의 이웃이 있다.
주어진 픽셀과 그 이웃들이 같은 instance 내에 있으면, 픽셀 사이 link를 positive로 설정하고 그렇지 않으면 negative로 설정한다.
예측된 positive 픽셀은 예측된 positive link를 통해 CC(Connected Components)로 결합된다.
이러한 방식으로 instance segmentation이 이루어지고, 각각의 CC가 발견된 text가 된다.
OpenCVdml minAreaRect와 같은 방법을 적용하여, 최종 detection 결과로 CC의 bounding box를 얻을 수 있다.
우리의 실험은 regression을 기반으로 하는 여러 방법들에 대해 여러 장점들을 보인다.
특히, 학습 횟수 또는 학습 데이터 수를 줄일 때, 여러 benchmark에서 비슷하거나 더 나은 성능을 보였다.
2. Related Work
2.1 Semantic & Instance Segmentation
segmentation은 이미지의 픽셀 단위로 라벨링을 하는 것이다.
픽셀이 object의 카테고리로만 고려되면 semantic segmentation이라고 하고, 주로 FCN(Fully convolution Networks)의 방법을 사용한다.
Instance segmentation은 각 픽셀에 대해 object의 카테고리 뿐만 아니라, instance의 구별도 해야하므로 semantic segmentation보다 더 어려운 과제이다.
이것은 물체 instance를 인식하기 위해 semantic segmentation보다 일반적인 object detection과 더 관련이 있다고 볼 수 있다.
그래서 최근 이 분야는 object detection 시스템을 많이 사용한다.
FCIS는 R-FCN의 position-sensitive 예측 개념을 확장한다.
Mask R-CNN은 Faster R-CNN의 RoI Pooling을 RoI Align으로 바꾸었다.
이들은 같은 모델에서 detection과 segmentation을 수행하며, segmentation 결과는 detection 성능에 크게 의존한다.
2.2 Segmentation-based Text Detection
Segmentation은 text detection에 오래 전부터 사용되었다.
Yao는 detection 문제를 세 가지 score map을 예측하는 sematic segmentation 문제로 보았다.
세 가지 score map은 text/non-text, character classes, chareacter의 link 방향이다.
그 다음 그들은 단어 또는 라인으로 그룹화된다.
TextBlock은 FCN으로 부터 예측된 saliency map으로부터 발견되고, 문자 후보들은 MSER을 사용되어 추출되었다.
나중에는 rule-base로 단어, 라인이 형성되었다.
CCTN에서는 coarse 네트워크가 text 영역 heat-map을 생성하여, 대략적인 text 영역을 찾기 위해 사용된다.
그렇게 찾은 영역은 fine text 네트워크를 통해 text line으로 정제되어, central line area heat-map과 text line area heat-map을 출력한다.
이런 방법은 오래 걸리는 후처리 단계와 좋지 못한 성능을 갖는다.
2.3 Regression-based Text Detection
이 방법의 대부분은 일반적인 object detection의 장점을 활용한다.
CTPN은 object detection의 anchor box 개념을 확장하여 text 조각을 에측하고, heuristic 방법으로 연결한다.
TextBoxes는 scene text가 가지는 큰 aspect ratio 특징에 맞게, 큰 aspect ratio의 anchor와 불규칙한 모양의 kernel을 사용한다.
RRPN은 scene text의 방향을 다루기 위해, anchor와 Faster R-CNN의 RoI Pooling 모두에 rotation을 추가하였다.
SegLink는 text segmentation을 예측하기 위해 SSD를 채택하였다.
EAST는 지역성을 인식하는 NMS를 사용하는 아주 조밀한 예측을 수행한다.
이런 모든 regression 기반의 text detection 알고리즘은 confidence와 location을 동시에 예측한다.
3. Detecting Text via Instance Segmentation
아래 사진에서 보면, PixelLink는 instance segmentation을 통해 text를 찾는다.
여기 instance segmentation에서, 예측된 positive pixel은 예측된 positive link를 통해 동일한 text instance로 묶인다.
그리고 이 segmentation 결과로부터 bounding box가 추출된다.

3.1 Network Architecture
SSD와 SegLink를 따라, feature extractor로 fully connected layer를 convolutional layer로 바꾼 VGG16이 사용되었다.
아래 사진을 보면, 모델은 text/non-text를 예측과 link prediction을 위한 2개의 헤더를 가진다.
둘 다 softmax를 사용하므로, 출력은 각각 1x2=2 와 8x2=16 채널을 가진다.

feature fusion layer의 2가지 setting이 있다.
1) PixelLink + VGG16 2s : { conv2_2, conv3_3, conv4_3, conv5_3, fc_7 }
2) PixelLink + VGG16 4s : { conv3_3, conv4_3, conv5_3, fc_7 }
2s의 해상도는 원본 이미지의 절반이고, 4s는 1/4이다.
3.2 Linking Pixels Together
주어진 픽셀과 링크에 대한 예측은 각각 threshold를 적용한다.
그런 다음, positive link를 사용하여 positive 픽셀이 묶이고, 각각의 발견된 text instance를 나타내는 CC들이 생성된다.
이렇게 되면 instance segmentation이 이루어진 것이다.
두 개의 이웃한 positive 픽셀이 주어지면, 두 픽셀로부터 그들의 link가 예측되고, 예측된 두 링크 중 하나라도 positive라면 그들은 연결된다.
이러한 linking 과정은 disjoint-set data structure을 사용하여 구현된다.
3.3 Extraction of Bounding Boxes
사실, detection 문제는 instance segmentation로 해결되었다.
하지만 IC13, IC15, COCO-Text와 같은 chanllenge 에서는 detection 결과로 bounding box가 요구된다.
그러므로 OpenCV의 minAreaRect와 같은 방법을 통해 CC들의 bounding box가 추출되어야 한다.
minAreaRect의 출력은 방향이 있는 사각형으로, IC15를 위한 다각형이나 IC13을 위한 사각형으로 쉽게 변형될 수 있다.
추가적으로, PixelLink에서는 scene text의 방향에 대한 제한이 없다는 것이 장점이다.
이 단계는, 위치 regression이 아니라 instance segmentation으로부터 bounding box를 얻는 다는 점에서, PixelLink와 regression 기반의 방법 간의 차이를 보여준다.
3.4 Post Filtering after Segmentation
PixelLink는 link로부터 픽셀을 그룹화하기 때문에, 노이즈 예측을 할 수 없어 후처리 단계가 필수적이다.
간단하면서 효율적인 방법은 발견된 box의 너비, 높이, 면적, 비율 등으로 필터링하는 것이다.
예를 들어, IC15 실험에서, 발견된 box가 10 픽셀보다 짧거나, 300픽셀보다 적은 영역을 가진다면 버려진다.
이 때, 10과 300이라는 수는 IC15 훈련 데이터셋의 통계적인 결과로 정해진 값이다.
특히, 선택된 필터링 기준으로, 훈련 데이터셋의 99퍼센트가 임계 값으로 선택된다.
예를 들어, 10은 IC15 훈련 데이터셋의 99퍼센트가 10 픽셀보다 길기 때문에, 최소 길이 사이즈로 선택되었다.
4. Optimization
4.1 Ground Truth Calculation
TextBlock의 공식에 따르면, text bounding box 내의 픽셀은 positive로 라벨링된다.
만약 overlapping이 존재한다면, overlap되지 않은 픽셀만 positive이고, 나머지는 negative 값을 가진다.
주어진 픽셀과 주변 8개 이웃 픽셀에 대해, 만약 그들이 같은 instance에 속한다면, 그들 사이의 link는 positive이고, 아니면 negative이다.
ground truth 계산은 예측 레이어의 모양으로 resize된 입력 이미지에 따라 수행된다.
예를 들어, 4s에 대해서는 conv3 3 / 2s에 대해서는 conv2 2
4.2 Loss Function
훈련 loss는 픽셀의 loss와 link의 loss의 합으로 사용된다.
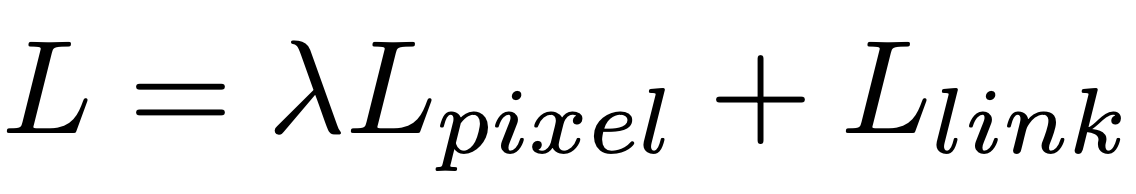
Llink는 positive 픽셀에서만 계산되기 때문에, 픽셀의 classification 문제가 link보다 더 중요하다.
그래서 λ를 2.0으로 설정한다.
Loss on Pixels
text instance의 크기는 매우 다양한다.
예를 들어 가장 위 사진의 'Manchester'는 다른 단어들의 합보다도 크다.
loss를 계산할 때, 만약 모든 positive 픽셀에 대해 같은 weight를 부여한다면, 작은 크기를 가진 instance에게는 불공평할 것이고, 성능에도 부정적인 영향이 끼칠 것이다.
이 문제를 해결하기 위해, segmentation을 위한 새로운 weighted loss인 Instance-Balanced Cross-Entropy Loss가 제안된다.
구체적으로 보면, 주어진 이미지의 N개의 text instance에 대해, 모든 intance에게 동일한 weight를 주면서 동일하게 처리한다.
Si의 넓이를 갖는 i 번째 instance에 대해, 모든 positive 픽셀은 wi = Bi / Si 의 가중치를 갖는다.

OHEM(Online Hard Example Mining)은 negative 픽셀을 고르는데 적용된다.
구체적으로 보면, weight를 1로 설정했을 때, 가장 높은 loss를 갖는 r x S 개의 negative 픽셀을 선택한다.
여기서 r은 negative-positive 의 비율로, 보통 3으로 설정된다.
위의 두 메커니즘은 모든 positive 픽셀과 선택된 negative 픽셀에 대해 W로 표시된 weight matrix를 생성한다.
픽셀 classification 문제에 대한 loss는 아래와 같다.
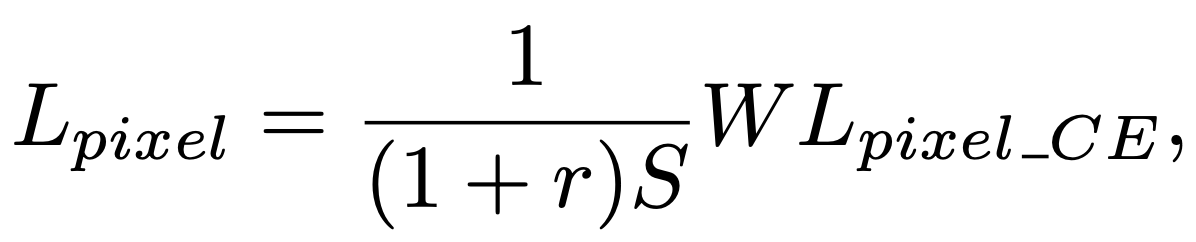
Lpixel_CE는 text/non-text 예측에 대한 Cross-Entrypy loss의 행렬이다.
결과적으로, 작은 instance의 픽셀은 큰 weight를 가지고, 큰 instance에 대한 픽셀은 작은 weight를 가진다.
그렇게 모든 instance가 loss에 동일하게 관여한다.
Loss on Links
postive와 negative에 대한 loss는 positive 픽셀에서만 분리되어 계산된다.
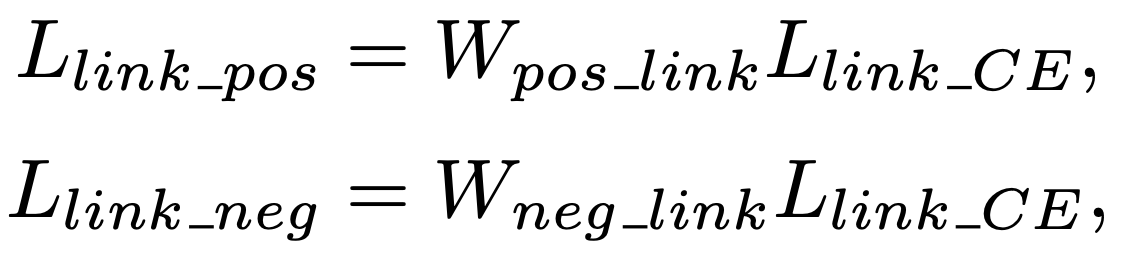
Llink_CE는 link 예측에 대한 Cross-Entropy loss matrix이다.
Wpos_link 와 Wneg_link는 각각 postive, negative link의 weight이다.
이들은 Lpixel 수식의 W로부터 게산된다.
자세히 보면, 픽셀의 k번째 이웃의 W는 아래와 같다.
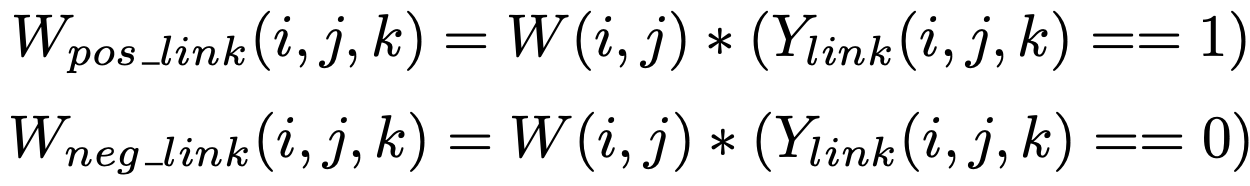
여기서 Ylink는 link의 label matrix이다.
link 예측의 loss는 일종의 class-balanced cross entropy loss로 아래와 같다.
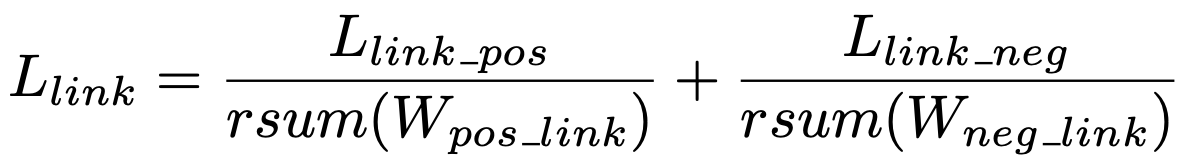
여기서 rsum은 reduce sum으로, tensor의 모든 요소를 scalar로 합한 값이다.
4.3 Data Augmentation
Data augmentation은 추가적인 임의의 rotation step을 하는 SSD와 비슷한 방법으로 수행되었다.
입력 이미지는 먼저, 20% 확률로 임의의 angle(0, π/2, π, 3π/2)로 회전된다.
그리고 임의로 10% ~ 100% 범위에서 자르고, 50% ~ 200% 범위에서 비율을 수정한다.
마지막으로 512x512 로 동일하게 resize한다.
augmentation 이후, 10픽셀보다 짧은 text instance는 무시된다.
무시된 instance의 weight는 loss 계산에서 0으로 설정된다.
5. Experiments
Pixellink 모델은 여러 benchmark에서 학습되고 평가되었다.
최신 방법들보다 같거나 나은 결과를 보였고, bounding box regression 없이 text localization 문제를 잘 해결함을 보여주었다.
detection 결과는 아래와 같다.

'논문' 카테고리의 다른 글
| Fast and Accurate Model Scaling 논문 정리 (0) | 2021.04.16 |
|---|---|
| ResNeSt : Split-Attention Networks 논문 정리 (0) | 2021.03.19 |
| SENet : Squeeze-and-Excitation Networks 정리 (0) | 2021.03.18 |
| ResNet / ResNext 정리 (0) | 2021.03.18 |
| Mask R-CNN 정리 (0) | 2021.03.17 |



