
취미가 좋다
Learning to Learn Single Domain Generalization 논문 정리 본문
Learning to Learn Single Domain Generalization 논문 정리
benlee73 2021. 5. 11. 16:33
Learning to Learn Single Domain Generalization
Fengchun Qiao, Long Zhao, Xi Peng
Abstract
우리는 학습시킬 수 있는 도메인은 하나인 반면, 여러 개의 새로운 도메인에서 잘 동작하는 모델을 만들고자 하는 worst-case 에서의 model generalization에 관심이 있다.
이러한 Out-of-Distrubution (OOD) 일반화 문제를 해결하기 위해 adversarial domain augmentation 이라는 새로운 방법을 제안한다.
The key idea is to leverage adversarial training to create “fictitious” yet “challenging” populations, from which a model can learn to generalize with theoretical guarantees.
핵심 아이디어는 adversarial 학습을 통해 가상이지만 도전적인 population을 만드는 것이다.
이 popultation은 모델이 일반화하는 방법을 배울 수 있도록 한다.
도메인 확장(augmentation)을 빠르고 바르게 하기 위해, meta-learning으로 모델을 학습하고 위에서 말한 worst-case 문제를 완화하기 위해 Wasserstein Auto-Encoder(WAE)를 사용한다.
1. Introduction
최근 몇년 동안, 여러 어플리케이션을 위한 머신 러닝 기반의 모델이 빠르게 배포되었다.
이러한 배경에는 훈련 데이터와 테스트 데이터가 비슷하다는 가정이 깔려있다.
그게 아니라면 deep neural networks와 같은 강력한 모델조차도 unseen or OOD 도메인에서 무너질 수 있다.
여러 도메인을 통합하여 학습하면 문제가 해결되지만, 여러 제약으로 항상 가능하지는 못하다.
그래서 다음과 같은 질문이 나온다.
하나의 소스 도메인으로부터 본 적 없는 여러 타겟 도메인으로 모델을 일반화할 수 있는가?
즉, 하나의 도메인으로부터 학습할 때, 어떻게 일반화 성능을 최대화할 수 있는가?
소스 도메인과 타겟 도메인의 불일치는 domain adaptation과 domain generalization에서 연구되어 왔다.
많은 연구와 성공이 있었음에도, 앞에서 언급한 single domain generalization 문제는 해결하지 못했다.
아래 그림의 c 와 같은 상황에서의 해결책이 필요하다.

이 논문에서는 해결책으로 adversarial domain augmentation을 제안한다.
최근 adversarial training 을 참고하여 이를 공식화하였다.
The goal is to use sin- gle source domain to generate “fictitious” yet “challenging” populations, from which a model can learn to generalize with theoretical guarantees.
목적은 하나의 소스 도메인으로 가상이면서 도전적인 populations를 생성하는 것이다.
이 populations 를 통해, 모델이 일반화될 수 있다.
그러나, 도메인 augmentation을 위한 adversarial 학습을 적용할 때, 기술의 한계가 있다.
소스 도메인과 크게 다른 가상 도메인을 생성하기가 매우 어렵다는 것이다.
다른 한편으로 많은 가상 도메인을 탐색하게 되면, 많은 계산 오버헤드를 발생한다.
이러한 한계를 완화하기 위해서, WAE 로 입력 공간에서 도메인 이동을 하여, worst-case 에서의 제약(constraint)을 완화한다.
더욱이, 앙상블 모델을 배우는 대신, 메타 학습을 통해 adversarial domain augmentation을 구성하여, single domain generalization이 잘 된 모델을 만든다.
2. Related work
Adversarial training
adversarial 공격에도 모델의 robustness를 향상시키는 학습 방법이다.
robustness뿐만 아니라 generalization 성능도 동시에 증가시킨다.
Meta-learning
초기화를 잘 시켜 새로운 task에도 잘 적응할 수 있도록 하는 여러 논문이 나왔지만, single domain generalization에 사용되지는 못한다.
그래서 우리는 single domain generalization을 위해 가상 도메인에서 모델을 효율적으로 학습하기 위한 MAML 기반의 메타 러닝 방법을 제안한다.
이렇게 학습된 모델이 새로운 타겟 도메인에서도 robust하다는 것을 보여준다.
3. Method
우리의 목적은 single domain generalization (sdg) 문제를 해결하는 것이다.
single domain generalization : 하나의 소스 도메인에서만 학습을 시키지만, 여러 새로운 도메인에서도 잘 일반화되도록 하는 것
이 문제를 해결하기 위한 좋은 방법은 adversarial training 을 활용하는 것이다.
The key idea is to learn a robust model that is resistant to out-of-distribution perturbations.

위의 식으로 worst-case 문제를 해결하여 모델을 학습한다.
D : 도메인 거리를 측정하는 similarity metric
S , D : source, target 도메인
ρ : S와 T의 가장 큰 도메인 불일치
θ : task 별 objective function L 에 따라 최적화된 모델의 파라미터
sup : supremum (상한)
E : expectation (평균)
세미콜론(;) 뒤의 값들은 식 L을 표현하기 위해 필요한 추가적인 정보(값)이다.
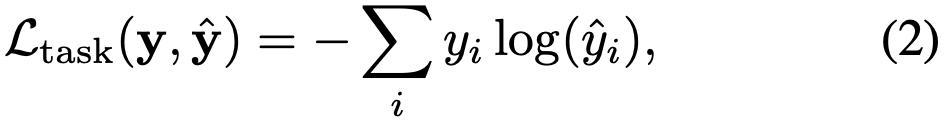
여기서는 cross-entropy loss를 사용하는 classification 문제에 중점을 둔다.
좌항의 y^ 는 모델 output에 softmax를 취한 결과이고, y 는 ground truth 클래스를 표현하는 one-hot 벡터이다.
우항의 yi 와 yi^ 는 i 번째 dimension에서의 y 와 y^ 이다.

worst-case formulation 1번 식에 따라, sdg 를 위한 Meta-Learning based Adverarial Domain Augmentation (M-ADA) 를 제안한다.
Fig. 2를 보면 우리 방식의 overview를 볼 수 있다.
3.1에서 adversarial training을 활용하여 “fictitious” yet “challenging” 도메인을 만든다.
3.2에서 worst-case constraint를 완화하는 WAE의 도움을 통해 확장된 도메인에서 학습한다.
3.3에서 task 모델과 WAE를 학습하면서, 도메인 augmentation 과정도 구성한다.
4에서는 worst-case guarantee를 증명하기 위한 이론을 설명한다.
3.1. Adversarial Domain Augmentation
여기서의 목표는 소스 도메인으로부터 여러 개의 augmented 도메인을 만드는 것이다.
augmented 도메인은 소스 도메인과 분산적으로 달라야하고, 발산하지는 않아야 한다.
이를 위해 Adversarial Domain Augmentation 을 제안한다.
task 모델과 WAE를 포함하는 우리의 모델은 위의 Fig. 2와 같다.
task 모델의 feature extractor 는 F : X → Z 로 입력 이미지를 input space에서 embedding space로 맵핑한다.
classifier 는 C : Z → Y 로 embedding space로부터 라벨을 예측한다.
X : image from input space
Z : image from embedding space
Y : predict label

z = F(x) 가 성립하도록, z가 x의 representation이라고 할 때, 위와 같은 loss function을 가진다.
Classification, Constraint 에 대한 식은 각각 위의 2, 1번 식과 같다.
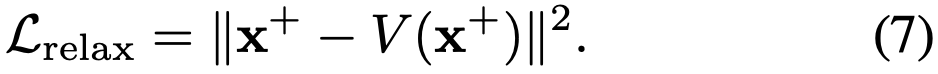
Relaxation 에 대한 식은 각각 위와 같다.
Relaxation의 ψ는 WAE의 파라미터이고, α, β 는 두 L의 균형을 맞춰주는 하이퍼 파라미터이다.

위의 loss function을 가지고 augmented 도메인 S+ 에서 adversarial 샘플 x+를 생산하도록 반복한다.
γ 는 gradient ascent의 learning rate이다.
충분한 perturbation를 생성하고 바람직한 adversarial sample을 생성하기 위해서는 조금반 반복해야한다.
perturbation : 작지만 모델을 속일만한 노이즈
Lconst는 S+ 가 D(S, S+) ≤ ρ 를 만족하도록, adversarial sample에 semantic한 consistency constraint를 부과한다.
구체적으로는, embedding space에서 S+와 S 사이의 Wasserstein 거리를 측정하기 위해서 "Generalizing to unseen domains via adversarial data augmentation" 논문을 따른다.
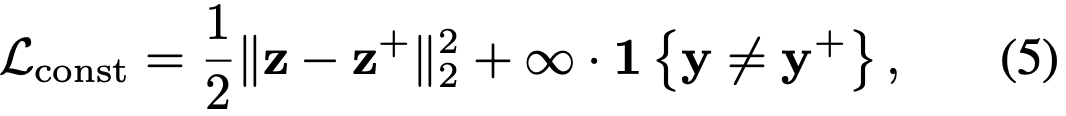
1{·} 는 0~1 indicator 함수이고, Lconst는 x+와 x의 클래스 라벨이 다를 때 ∞ 가 된다.
indicator function : 조건(집합에 포함되는지)이 참이면 1을 반환하고, 거짓이면 0을 반환
Lconst는 Wasserstein 거리로 측정된 소스 도메인 밖에서의 generalization 성능을 조절한다.
그러나 Lconst는 샘플과 perturbations 사이의 semantic distance를 제한하므로, 제한된 도메인 이동을 만든다.
그래서, Lrelax 가 semantic consistency constraint를 완화시키기 위해 제안되었고, 큰 도메인 이동을 만든다.
3.2. Relaxation of Wasserstein Distance Constraint
우리는 확장된 도메인 S+ 가 소스 도메인 S와 크게 다를 것으로 기대한다.
다시 말해, S+ 와 S 사이의 도메인 discrepancy(불일치)를 최대화하고 싶다.
그러나 semantic consistency constraint Lconst 가 S → S+ 인 도메인 이동을 크게 제한하기 때문에, 올바른 S+ 를 생산해야하는 새로운 과제가 주어진다.
이 문제를 해결하기 위해서, 우리는 도메인 밖으로 augmentation 하는 Lrelax를 제안한다.
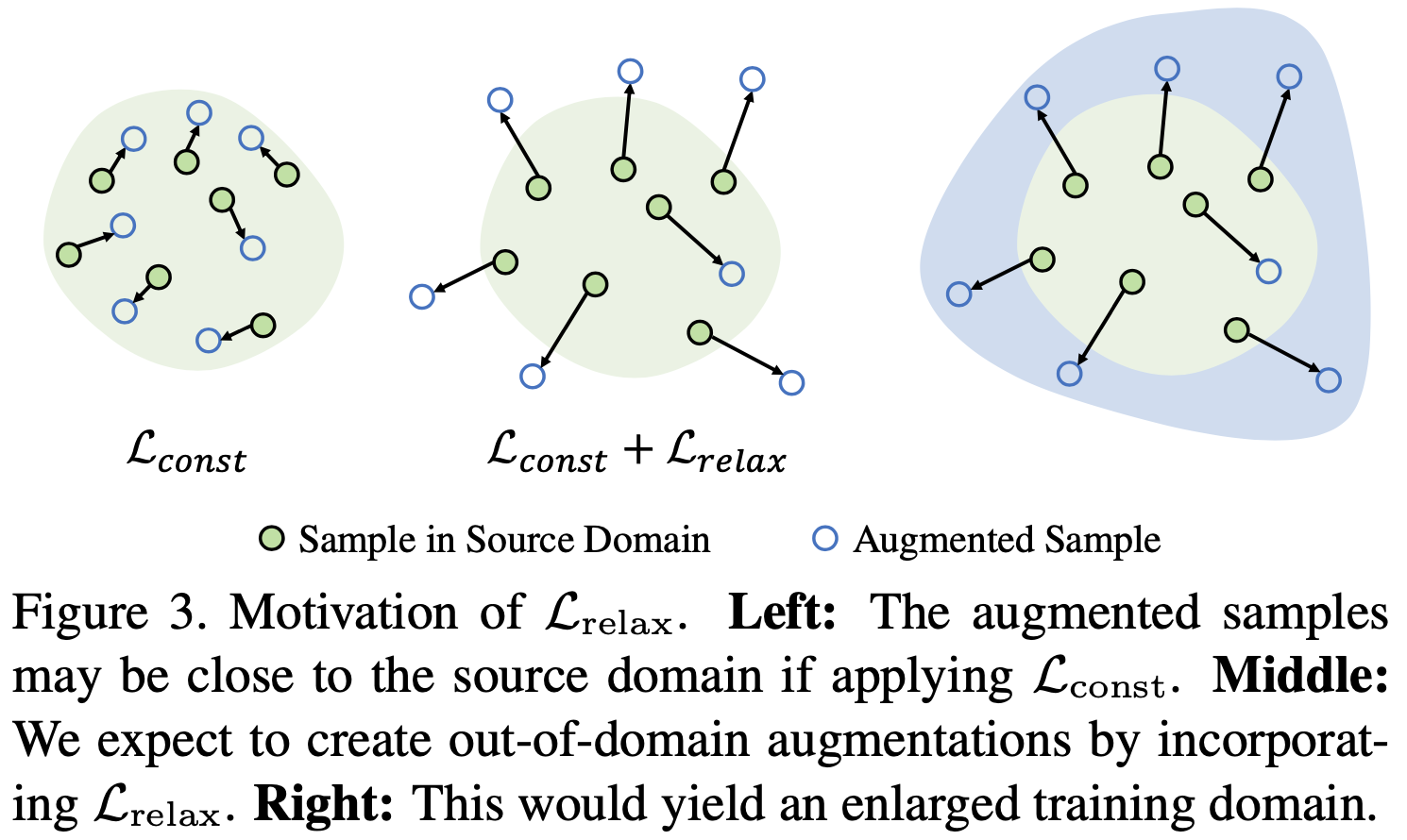
이 아이디어를 표현한 것이 위의 그림이다.
이 Lrelax를 구현하기 위해 Wasserstein Auto-Encoders (WAEs) 를 사용한다.
V는 ψ를 파라미터로 갖는 WAE 라고 하자.
V는 Q(e|x) 인코더와 G(x|e) 디코더로 구성되고, x와 e는 각각 입력과 bottleneck embedding 이다.
추가적으로 우리는 Q(x)와 이전 distribution(분포) P(e) 사이의 차이를 측정하기 위해 distance metric De를 사용한다.
De는 Maximum Mean Discrepancy(MMD) or GANs 로 구현된다.
그렇게 다음 식을 최적화하여 V를 배운다.

여기서 λ는 하이퍼 파라미터이다.
소스 도메인 S 에서 V를 pre-training한 후 freezing 하고, domain augmentation을 위해 reconstruction error를 최대화한다.
Vanilla 나 VAE와 달리 WAE는 input과 reconstruction 사이의 distribution 를 측정하기 위해 Wasserstein metric을 사용한다.
그래서 pre-trained 된 V는 소스 도메인의 distribution을 더 잘 이해할 수 있고, Lrelax가 최대화되어 더 큰 도메인 이동이 일어난다.
V는 augmentation이 소스 도메인 밖에 있는지에 대한 여부를 판별하는 one-class discriminator 역할을 수행하고, 이것이 기존 GAN의 discriminator와의 차이점이다.
또한 하나의 소스도메인만 사용하기 때문에, domain adaptation과도 큰 차이가 있다.
결과적으로, Lconst 와 Lrelax를 같이 사용하면서, input space에서 S+를 밀어내는 동시에 embedding space로 S+를 당기는 효과가 있다.
3.3 Meta-Learning Single Domain Generalization
소스 도메인 S 와 augmented 도메인 S+ 에서 모델을 효율적을 학습하기 위해, meta-learning scheme(체계, 기법) 를 활용한다.
소스 도메인 S와 타겟 도메인 T 사이의 도메인 이동을 따라하기 위해, 학습할 때 각 iteration에서 S에서는 meta-train, S+에서는 meta-test를 수행한다.
그렇게 iterations 후에 모델은 최종 T에 대해 좋은 일반화 성능을 가질 것으로 예상된다.
제안된 Meta-Learning based Adversarial Domain augmentation (M-ADA)는 각 iteration에서 3개의 파트로 나뉜다.
3개의 파트는 meta-train, meta-test, meta-update 이다.
meta-train 에서는, 소스 도메인의 샘플들로부터 Ltask 가 계산되고, 모델 파라미터 θ 가 gradient step으로 인해 업데이트된다.

meta-test 에서는, 각 augmented 도메인 Sk+로부터 Ltask(θ^; Sk+) 를 계산한다.
meta-update 에서는, meta-train 과 meta-test 가 동시에 최적화 되는 결합된 Loss로 부터 계산된 gradient로 θ 를 업데이트한다.

K는 augmented 된 도메인의 개수이다.

위 알고리즘은 전체 학습 파이프라인을 요약한 것이다.
이 방법은 다음의 장점이 있다.
첫 번째, 앙상블 모델을 학습한 이전 논문과 달리, 효율성을 위해 단일 모델을 사용한다.
우리가 제한한 M-ADA가 이전 논문보다 메모리, 속도, 정확도 측면에서 좋은 성능을 보인다.
두 번째, meta-learning scheme 는 빠른 적응을 위한 학습된 모델을 준비한다.
이는 few-shot domain adaption이 가능하도록 한다.
6. Conclusion
single domain generalization 문제 해결을 위해 M-ADA 를 제안하였다.
'논문 > Domain Adaptation & Generalization' 카테고리의 다른 글
| Progressive Domain Expansion Network for Single Domain Generalization 논문 읽기 (0) | 2021.06.15 |
|---|---|
| Do Adversarially Robust ImageNet Models Transfer Better? (0) | 2021.05.04 |
| Bidirectional Learning for Domain Adaptation of Semantic Segmentation 논문 정리 (0) | 2021.05.04 |
| CyCADA: Cycle-Consistent Adversarial Domain Adaptation 논문 정리 (0) | 2021.05.04 |
| Adversarial Discriminative Domain Adaptation 논문 정리 (0) | 2021.05.04 |



