
취미가 좋다
[ 데이터 인프라 ] Kafka Streams, kSQL, ksqlDB, Apache Flink, Spark Structured Streaming 본문
[ 데이터 인프라 ] Kafka Streams, kSQL, ksqlDB, Apache Flink, Spark Structured Streaming
benlee73 2021. 8. 25. 12:10Stream Processing
이전 글에서 설명한 스트리밍 플랫폼의 event producer들이 스트림을 발생하면, 플랫폼을 통해 흘러서 여러 곳으로 보내지게 된다. 그 과정에서 이벤트들을 중간에서 처리하는 부분이다.
batch로 처리하거나 실시간으로 처리할 수 있다. kafka는 실시간으로 처리하고, spark는 micro batch로 처리한다.
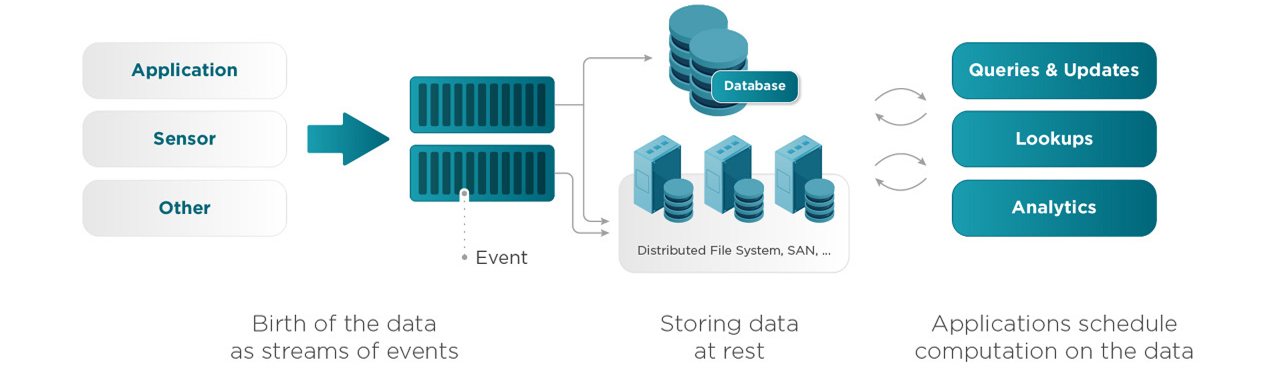
아래의 사진처럼 producer에서 만든 이벤트와, Database의 변경사항을 kafka에 싣는다.
그렇게 받은 이벤트 스트림들을 kafka consumer에서 가져가거나, connect sink를 통해 target DB에 저장한다.
그 중간에서 kafka streams, KSQL을 통해 스트림에 대한 처리를 한다.
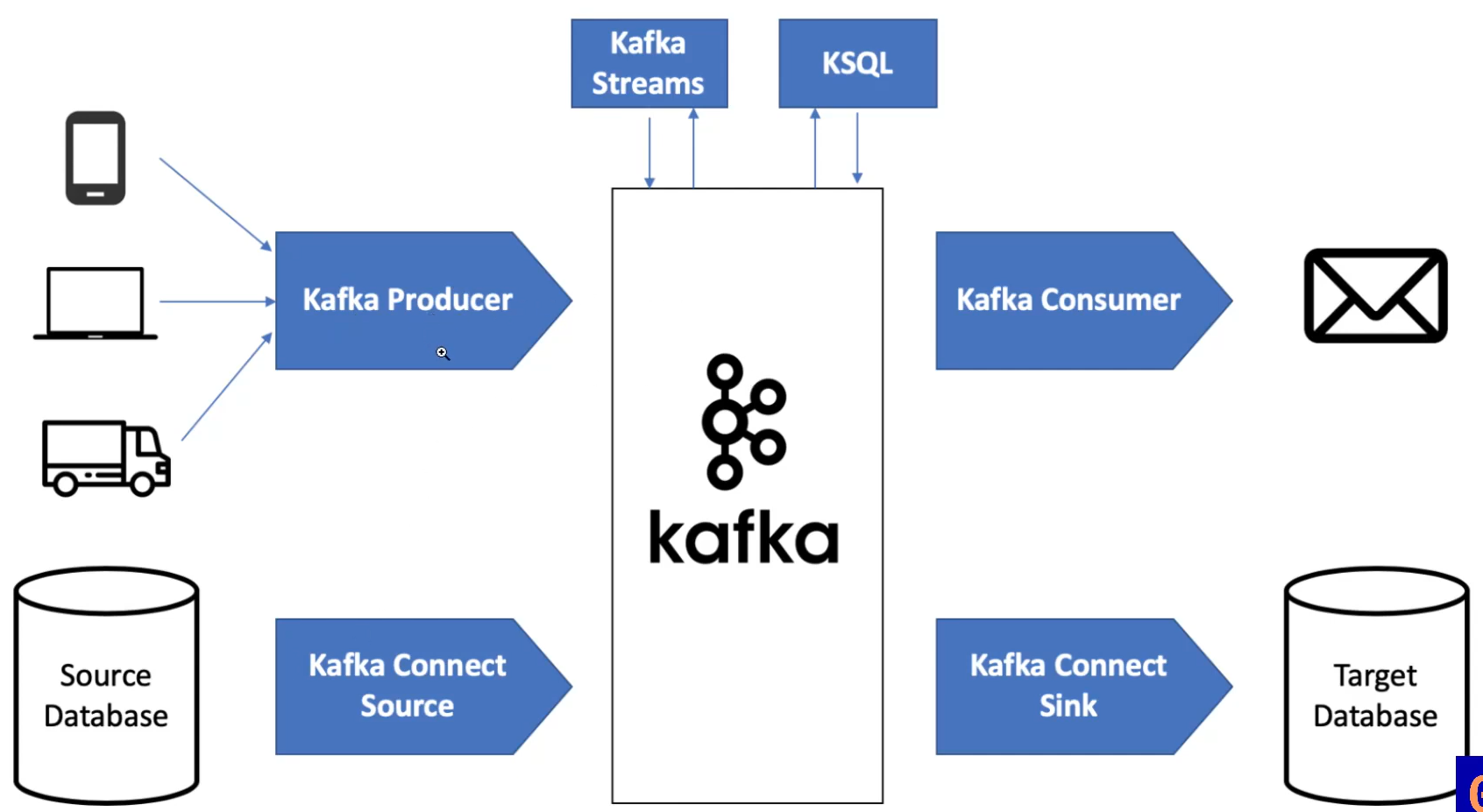
1. Kafka Streams
kafka steams api 로 kafka의 데이터를 읽어서 빠르게 처리를 하고, 다시 kafka에 저장한다.
JVM client 라이브러리로, 자바로 코딩하여 사용하고, 컨테이너나 vm 등 어플리케이션을 실행하여 사용한다.
우리의 어플리케이션은 kafka cluster 밖에 있고, kafka와 streams api를 통해 데이터를 주고 받는다.

1.1) stateless processing
기존의 상태에 상관 없이 무조건 처리 하나를 하는 것
예를 들어, 들어온 수에 특정 수를 곱하는 작업은 이전 상태를 고려하지 않아도 된다.
1.2) stateful processing
기존의 상태를 참고하여 처리를 하는 것
예를 들어, 숫자를 세야하는 작업은, 이전에 얼마까지 셌는지를 고려해야 한다.
또는 광고 노출 & 광고 클릭 데이터를 가져와서 join 할 때, stateful operation을 사용한다.
1.3) windowing operations
어느정도의 기간으로 처리할 것인지에 대한 기준
예를 들어, 숫자를 세야할 때, 10초 동안 세거나 하는 기준이 된다.
즉, 위의 3개의 처리 방법으로, 이벤트를 가져올 때, 원하는 방식으로 처리해서 가져올 수 있다.
1.4) KStream & KTable
원래 kafka api는 producer와 consumer를 가지고 만들 수 있지만, 더 쉽게 사용하기 위해 KStream, KTable을 만들었다.
그래서 자바 코드로 kafka streams를 사용할 수 있다.

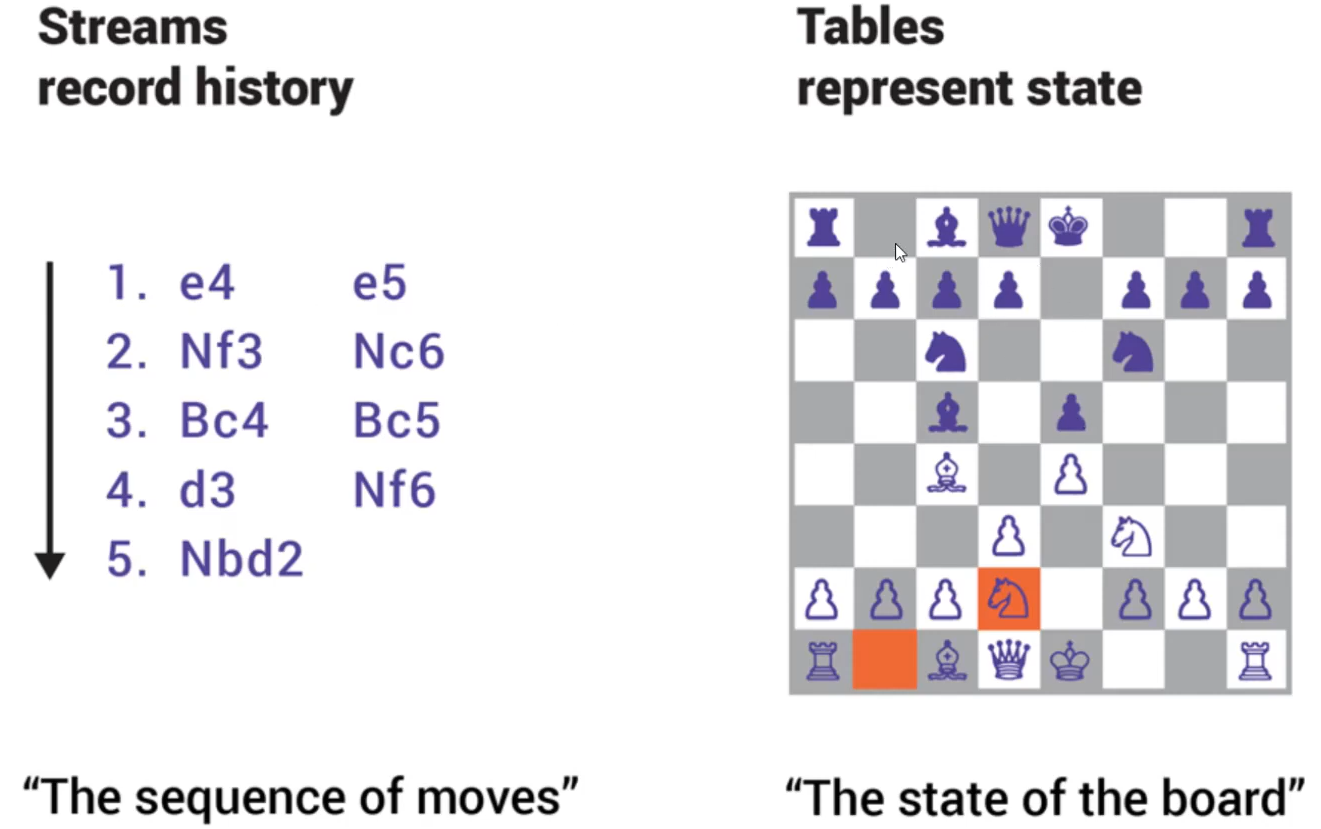
2. KSQL
위의 KStream, KTable보다 쉽게 만든 것으로, SQL로 스트림 처리를 할 수 있다.
SQL 문장으로 "1분 동안에 에러가 몇 번 발생하였는가", "특정 시간 내에 결제가 몇 번 이루어졌는가" 등을 할 수 있다.
자바가 아니라 SQL로 하기 때문에 더 편하다.
kafka cluster 밖에 ksql을 처리하는 별도의 cluster가 있다.

3. ksqlDB
위의 두 cluster를 관리하기가 번거로워서 새로 만든 DB로, 아래 2가지 기능이 추가되었다.
3.1) Pull queries
우버 서비스를 이용할 때, ksql을 사용하여 변경되는 차량 위치를 계속 받아올 수 있고, 이를 push 쿼리라고 한다.
pull 쿼리는 현재 데이터만 가져오는 방식으로, 실제 데이터베이스처럼 동작한다. 이 기능을 추가했다.
3.2) Connector management
ksql은 kafka cluster 밖에 있었기 때문에, 어떤 데이터를 가져올 지에 대해서 kafka cluster 내에 따로 설정해야 했다.
하지만 ksqlDB는 그 안에서 connection을 만들 수 있다. 어떤 데이터를 가져와서, sql로 처리하고, 다시 넣을 것인지 ksqlDB 내에서 처리할 수 있어서 더 간편해졌다.
아래의 과정 전체를 ksqlDB 안에서 한 번에 처리할 수 있어서, kafka cluster를 만들고 kafka steams cluster나 ksql cluster를 따로 만들 필요가 없어졌다.

기존에는 왼쪽처럼 DB connector, kafka cluster, stream processing cluster(spark, flink...) 등을 만들어야 했다.
ksqlDB를 사용하면, 하나로 묶어서 처리할 수 있다. kafka에 올라가는 모든 데이터, 이벤트 스트림들을 sql로 원하는 대로 처리해서, kafka stream에 올리거나, DB에 저장할 수 있다.


4. Apache Flink
데이터 스트림에 대해서 stateful computations를 실시간으로 수행하는 플랫폼이다.
kafka와 비슷하다. stream&batch 처리가 가능하고, api로 구성되어 Java/Scala/Python 에서 실행할 수 있다.
5. Spark Structured Streaming
Spark는 아래와 같이 micro batch processing을 사용한다.
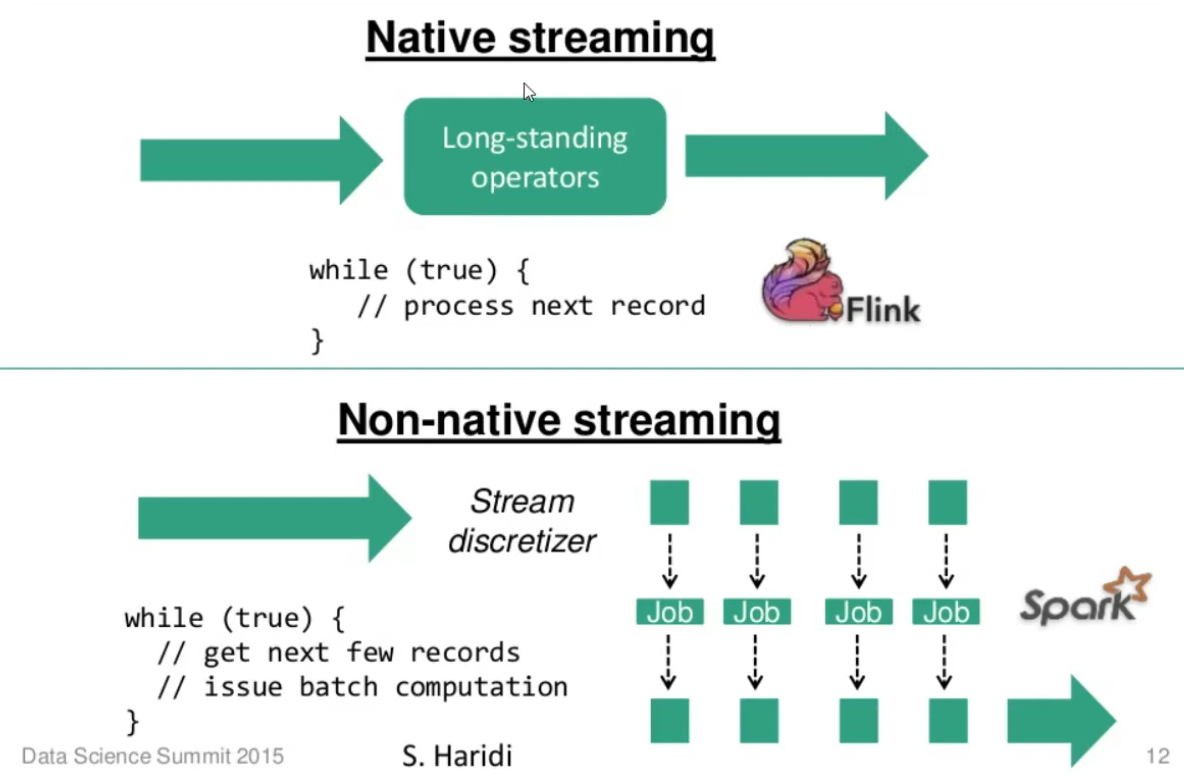
kafka 와 비슷하여, 회사 상황에 맞게 선택하여 사용하면 된다.
Spark 플랫폼을 쓰고 있으면 Spark Streaming, kafka cluster를 사용하고 있으면 ksqlDB를 사용하면 된다.
Stream Processing은
내부에서 stream으로 쏟아지는 데이터를 엮어서 처리하고,
Data Warehouse나 Data Lake에 저장할 때 사용한다.
참고
https://youtube.com/playlist?list=PLL-_zEJctPoJ92HmbGxFv1Pv_ugsggGD2
최신 데이터 인프라 이해하기
www.youtube.com
'Data Engineer > 데이터 인프라' 카테고리의 다른 글
| kafka 카프카 쉬운 간단 정리 (1) | 2023.09.21 |
|---|---|
| [ 데이터 인프라 ]Kafka, Pulsar, Kinesis (0) | 2021.08.25 |
| [ 데이터 인프라 ] Spark, Python, Hive (0) | 2021.08.24 |
| [ 데이터 인프라 ] Data Modeling, Worflow Manager (0) | 2021.08.24 |
| [ 데이터 인프라 ] ETL/ELT 도구들 (Connectors) (0) | 2021.08.24 |



