
취미가 좋다
[ 데이터 인프라 ]Kafka, Pulsar, Kinesis 본문
Data Streaming
클라우드 이전 시절, Data Warehouse만을 사용하였고, 많은 데이터를 저장할 수 없으니, 엄격한 schema를 사용하여 분석을 위한 데이터만을 뽑아 저장하였다. 데이터를 읽어오기 위해서는 ETL의 Load가 끝난 시점부터 가능했고, BI 툴을 이용하여 접근할 수 있었다.
하둡의 Batch 시스템이 나오고나서, 다양한 schema를 사용할 수 있었지만, 여전히 배치의 데이터 Load 이후 데이터 접근이 가능했다. 그래도 programmable한 접근(언어를 이용한)이 가능하였다.
Streaming이 나오고나서, 다양한 schema뿐 아니라 Ingestion(데이터를 빼오는 시점)이 끝나면 바로 접근이 가능해서 실시간으로 접근할 수 있었다. Batch와 마찬가지로 Programmable한 접근이 가능하다.
그래서 데이터 가용성때문에 실시간 스트리밍이 중요하다.

이전 글의 Spark도 Streaming을 지원한다고 했지만, 사실 아주 작은 배치를 사용한 것으로 실시간 처리처럼 보인 것 뿐, 실제 streaming은 아니다. native streaming은 데이터 하나하나 처리하는 것이다.
스트리밍 데이터는 수천 개의 데이터 원본에서 연속적으로 생성되는 데이터이다.


1. Kafka
: 오픈소스로 된 distributed event streaming platform으로 링크드인에서 개발되었다.
: 실시간으로 스트리밍되는 이벤트 기반의 어플리케이션 개발을 가능하게 해주는 플랫폼
데이터를 주고받는 어플리케이션 & 서비스가 많아지면서 전체 시스템이 복잡해지고, 유지 보수가 어려워졌다. 카프카를 두어, 소스 어플리케이션(producer)이 데이터를 카프카로 보내면, 카프카는 이를 토픽(queue)에 저장하고, 타겟 어플리케이션(consumer)이 데이터를 가져가도록 한다. producer와 consumer는 라이브러리로 되어 있어서 어플리케이션에서 구현 가능하다. 이터가 많은 회사에서는 표준처럼 사용된다.

1.1) Publish / Subscribe Messaging
수많은 서버에서 어플리케이션 메트릭을 수집할 때, 직접 연결하려고 하면 너무 복잡하다.
그래서 중앙에 Publish / Subscribe Messaging 시스템이라는 것을 만든다.
여러 서버들이 Publisher가 되어 메트릭을 던지고, subscriber가 그 메시지를 받아간다.


하지만 이벤트로 스트리밍되는 데이터(log, tracking)가 더 메트릭만 있는 것이 아니다.
그럴 때마다 pub/sub 시스템을 구축하기 어렵기 때문에, 이를 통합한 시스템을 만든 것이 kafka이다.

1.2) Kafka의 모델
kafka는 두 모델(Queueing, Publish-Subscribe) 을 합친 것이라 볼 수 있다.


1.3) 특징
- High Throughput : 빠른 처리
- Scalable : 무한히 확장 가능
- 전달되는 이벤트 스트림을 내부에 분산해서 안전하게 저장
- 고가용성
- 스트림 프로세싱 기능들이 내장되어 있음
- 여러 프로그래밍 언어로 접근할 수 있음
1.4) kafka 사용 용도
여러 곳에서 이벤트가 쏟아지고, 다른 곳들로 보내져야할 때 사용하는게 적합하다.

1.5) kafka 아키텍쳐
여러 Producer와 Consumer가 있다.
kafka 클러스터 안에 여러 Broker(kafka 서버)가 메시지를 복제하여 토픽으로 가지고 있다. 토픽은 하나의 테이블이라고 보면 된다. 토픽을 분산해서 가지는 이유는 서버가 다운되더라도 안전하기 때문이다.
producer가 토픽에 메시지를 푸시하면, consumer들이 한번만 가져간다.
zookeeper를 따로 두어서 서버를 관리한다.


메시지가 전달되면 토픽의 파티션에 저장된다. 파티션을 늘림으로써 쓰는 속도를 향상시켰다.
단, 파티션을 늘리면 줄이는 것이 불가능하다는 단점이 있다.
1.6) kafka APIs
| Admin API | 토픽이나 브로커(서버)들을 관리한다. |
| Producer API | 이벤트를 만든다. |
| Consumer API | 이벤트를 읽는다. |
| Kafka Streams API | Producer가 만든 이벤트로 스트림 프로세싱을 처리한다. |
| Kafka Connect API | 다양한 외부 시스템(DB, 어플리케이션)과 연결한다. |
1.7) kafka streaming platform
카프카가 회사 내 시스템에서 동작하는 방식이다.
먼저 여러 Producer들이 connector를 통해 이벤트들을 쏟아낸다.
실시간 이벤트들을 토픽별로 정리를 하고, kafka stream을 통해서 스트림을 처리(join, 변환)한다.
또다른 connector를 이용해서 여러 consumer로 보낸다.
회사 내 모든 스트림을 한 곳으로 모을 수 있고, 실시간으로 처리할 수 있다.
흘러가는 모든 것들이 영구적으로 저장되고, 들어온 이벤트에 처리도 한다.

1.8) confluent
kafka 기반의 에코시스템으로, kafka를 만든 사람들이 나와서 만든 회사.
kafka에 대시보드, audit 등을 붙여서 만들어서, 사용하기 쉽도록 만들었다.
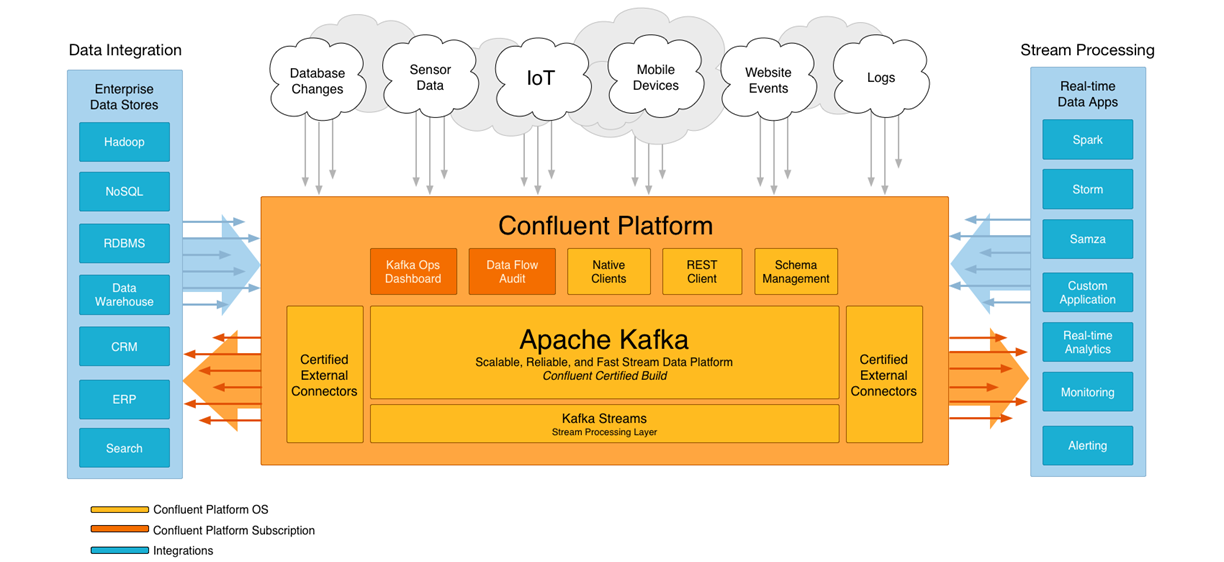
2. Pulsar
클라우드용 distributed messaging and streaming 플랫폼이다.
확장이 가능하고, 속도도 빠르고, 영구적으로 저장 가능하고, 다양한 언어 사용이 가능하다.
기능상으로 kafka와 비슷하다.
bookkepper를 사용하여 저장한다는 것이 다르다. kafka는 파티션을 쪼개서 저장한다면, pulsar는 segment 단위로 쪼개서 저장한다. 이외에도 kafka와 비교하는 내용은 매우 많다.
3. Amazon Kinesis
아마존이 만든 스트리밍 플랫폼이다. 형식 자체는 kafka와 비슷하다.
하지만 성능면에서 kafka가 좋기 때문에, 웬만하면 kafka를 사용하는게 좋다.
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
아마존은 kafka를 올려서 사용하기 편하도록 하도록 제공한다.
참고
https://youtube.com/playlist?list=PLL-_zEJctPoJ92HmbGxFv1Pv_ugsggGD2
최신 데이터 인프라 이해하기
www.youtube.com
'Data Engineer > 데이터 인프라' 카테고리의 다른 글
| kafka 카프카 쉬운 간단 정리 (1) | 2023.09.21 |
|---|---|
| [ 데이터 인프라 ] Kafka Streams, kSQL, ksqlDB, Apache Flink, Spark Structured Streaming (0) | 2021.08.25 |
| [ 데이터 인프라 ] Spark, Python, Hive (0) | 2021.08.24 |
| [ 데이터 인프라 ] Data Modeling, Worflow Manager (0) | 2021.08.24 |
| [ 데이터 인프라 ] ETL/ELT 도구들 (Connectors) (0) | 2021.08.24 |



